
Click to imagine.
Ver. 0.2 aggiornata al 5/9/2022
Disclaimer:
Non ho assolutamente la pretesa di avere la verità in tasca, anzi, auspico di riuscire a capire qualcosa di più proprio grazie al confronto che questo testo potrebbe generare con i suoi lettori. Questa è una riflessione e una esposizione quanto più immediata e discorsiva possibile delle prime conclusioni a cui sono arrivato su un argomento che è potenzialmente infinito.
Sono felice se aggiungerà qualcosa al discorso su questa materia artistica, fosse anche per segnare un vicolo cieco sulla mappa delle possibili speculazioni.
Questo testo è in continuo aggiornamento e mi scuso per eventuali errori di battitura o imprecisioni (o le è maiuscole con l’apostrofo), cercherò di correggere ogni imperfezione e di tenerlo aggiornato finchè avrà senso farlo.
Elenco delle versioni precedenti:
Prefazione
Questo è un testo sul modo in cui ci stiamo relazionando a una nuova, incredibile tecnologia: le AI text to image (TTI).
L’entusiasmo è giustamente alle stelle trattandosi di uno dei traguardi più sconvolgenti della tecnologia legata alla produzione di immagini digitali.
Una premessa rapidissima: sono un artista, amo disegnare e ometterò quella parte del discorso in cui vi annoio col fatto che nonostante io adori la tecnologia, non c’è innovazione tecnologica che possa togliermi il piacere di mettermi a disegnare, per misurarmi con me stesso e con la meraviglia della vita.
Per me è un concetto ovvio, ma mi sembra giusto comunque farvi accenno perché sia chiaro che sono cose che tengo perfettamente a mente mentre scrivo; tuttavia sono irrilevanti ai fini del discorso.
Il problema che vado sollevando è una questione di nomenclatura nel mondo dell’arte e della creatività. Mi sembra che questo problema abbia radici antichissime, ben più lontane nel tempo della nascita delle AI text to image, radici che affondano nella diseducazione al visuale e a costrutti gerarchici antichi.
Il nostro modo di pensare e reagire alle AI text to image è un sintomo, e non la causa, di una mancanza di dimestichezza con le arti visive.
artifìcio (o artifìzio) s. m. [dal lat. artificium, der. di artĭfex «artefice»]. – 1. a. Uso dell’arte per ottenere fini determinati, quindi abilità, maestria nell’operare. b. Espediente trovato con arte per raggiungere un migliore effetto, per creare un’illusione, per far apparire più bella una cosa. Quindi anche astuzia, stratagemma.
Capitolo 1
Ho avuto un’idea
Non abbiamo certezze in merito, ma gli esperti sono abbastanza concordi che i primi sviluppi del linguaggio umano risalgano perlomeno a centosessantamila anni fa e che la sua complessità ci distingue da tutte le altre specie animali.
In passato si credeva che il linguaggio umano avesse la funzione principale di comunicare, mentre recentemente si è sviluppata e ha trovato credito una diversa teoria, secondo cui la funzione primaria dei linguaggi è la creazione, interpretazione e gestione del pensiero.
La comunicazione avanzata ne è un effetto collaterale: ad esempio i cani sono in grado di comunicare fra loro in maniera più semplice, non avendo sviluppato un linguaggio complesso come il nostro alla base del loro pensiero.
Alla base di un linguaggio c’è la semiosi, che è quel processo che assegna un significante, sia esso un segno, un gesto, un suono o una parola, a un significato, ovvero quello che si vuole provare a dire, quello che se ne capisce: dare un nome a una cosa o a una sensazione o a un concetto astratto. L’idea sta nel mezzo fra il cosa e il nome. È l’immagine mentale che pensiamo del cosa e può avere conseguenze diverse: può farci sovvenire una visione, un suono, una sensazione o un concetto. La semiosi è particolarmente interessante perché questa connessione a tre vie funziona anche quando del cosa originario non c’è traccia: probabilmente una funzione primigenia del linguaggio è stato proprio di segnalare la presenza di un predatore dietro l’angolo, senza doverlo vedere negli occhi per poterne avere a mente l’idea, immaginare la sensazione di pericolo, provare paura e quindi scappare con la giusta convinzione assieme agli altri che il predatore lo hanno appena visto rischiando la vita.
Una parola o un gesto sono particolarmente potenti perché riescono anche nel miracolo di non farci concentrare necessariamente sui dettagli irripetibili di ogni singolo predatore sul pianeta terra, possiamo generalizzare. “Tigre!” o “Groarrr!” e l’immagine mentale minima indispensabile di predatore spaventoso — sia essa di quella specifica tigre che conosciamo tutti e due, di una qualsiasi tigre, o dell’orso che ha in mente il mio interlocutore abruzzese — in un istante ha già fatto il suo lavoro.

Scott McCloud, Capire il fumetto.
Interessantissima la posizione delle parole nello schema triangolare di Scott Mc Cloud nel suo “Capire il Fumetto” (un testo incredibile di comunicazione visiva che dovrebbero leggere tutti, a prescindere del proprio medium di elezione): sono tutte a destra, oltre al pittogramma. Sono la forma di stilizzazione del pensiero più sofisticata possibile, informazioni quantizzate, digitali, ad altissimo valore concettuale e perfino più generalizzanti e astratte di un pittogramma.
idèa s. f. [dal gr. ἰδέα, propr. «aspetto, forma, apparenza», dal tema di ἰδεῖν «vedere»]. – 1. a. Nel sign. più ampio e generico, ogni singolo contenuto del pensiero, ogni entità mentale, e più in partic. la rappresentazione di un oggetto alla mente, la nozione che la mente si forma o riceve di una cosa reale o immaginaria
Eppure l’etimologia della parola idea è molto interessante, perché ha a che fare proprio con le immagini, non con le parole. La semiosi, infatti, può avvenire con diversi medium di output. L’uomo impara a parlare sicuramente dopo aver sviluppato un sistema di semiosi e quindi di pensiero fondato sulle immagini e sui suoni. Già nelle pitture rupestri della Val Camonica o nel sistema di scrittura egizio è possibile distinguere chiaramente simboli grafici ideogrammatici e pittografici, in cui ogni disegno funziona come un “nome” per un concetto astratto e non come rappresentazione della realtà. Sono simboli collegati a un’immagine mentale non reale, a un puro concetto visuale. L’uomo non è solo capace di pensare per immagini, ma è in grado anche di idearne, appunto, e quindi di produrre immagini sintetiche che possono quindi non avere nulla a che vedere con la rappresentazione fedele della realtà naturale fenomenica. Da bambini impariamo a comprendere per primo un linguaggio visivo e tutti i bambini imparano a disegnare prima di parlare, dimostrando quindi che la semiosi per immagini è indipendente dalla semiosi per parole.
Non esiste un collegamento necessario fra concetto come parola e come immagine.
L’uomo è in grado di creare le immagini in un processo mentale esclusivamente visivo: l’ideazione avviene senza usare le parole. Tuttavia, come puntualizzava giustamente Peter Greenaway in una sua intervista a RAI Cultura del 2017 , il pensare per immagini è un’attività che scolasticamente viene rimpiazzata dallo studio della parola. I libri con le immagini diventano per bambini e spiegarsi a disegni o studiare le figure viene visto come un sistema infantile di espressione e lettura. In Italia bisogna aspettare gli studi universitari per affrontare seriamente lo studio di un qualsiasi linguaggio visivo. Nonostante sia il nostro primo strumento per comprendere la realtà e per comunicare le nostre idee, a 20 anni siamo poco più che analfabeti del linguaggio visuale. Possiamo sicuramente provare a descrivere a parole un’immagine mentale, o farci ispirare un’immagine da un concetto parlato, ma si tratta sempre di dover produrre una nuova forma, un nuovo significante, su un altro medium — una transustanziazione impossibile senza che ci sia uno stravolgimento del significato. Cosa decisamente diversa dall’operare direttamente fra immagine della mente e immagine su un supporto.
Mattia Traverso, un mio caro amico ed eccezionale game designer, mi ha proposto un punto di vista inedito dicendomi: “Anche la vita può essere vista sostanzialmente come un medium. Noi poi la traduciamo in memorie di vario genere; è uno stream continuo di stimoli di cui fruiamo e con cui interagiamo. Portare un medium interattivo esclusivamente individuale e multi sensoriale qual è la vita su altri supporti non è facile, è un’impresa, ma abbiamo tanti modi di esprimerci sui vari canali sensoriali.” Imparare ad osservare e ad ascoltare, che lo si faccia con uno spirito di ricerca o di abbandono, è uno degli inviti più ricorrenti che troverete su qualsiasi testo che parli dell’arte e della comunicazione in generale. Le idee che si formano dentro di noi, siano esse visive o fatte di parole, restano impigliate nella nostra mente come farfalle in un retino. Possono interagire fra di loro olisticamente e creare una rete di pensiero in cui i ponti che le collegano diventano nuovi concetti, oppure possono restare impresse dentro di noi tutta la vita, cristallizzate, come accade alla memoria di una terribile esperienza.
Infine una nota sul rapporto fra volontà, idea e corpo.
Carmelo Bene, ospite da Maurizio Costanzo per un famosissimo, ormai leggendario, incontro con il pubblico disse:
“Il linguaggio crea dei guasti ed è fatto solo di buchi neri, è fatto solo di guasti. “Codesto solo” dice l’Eusebio nazionale, cioè Eugenio Montale, però traducendo pari pari Nietzsche, ebbene: “Codesto solo oggi possiamo dirti, ciò che non siamo, ciò che non vogliamo.” Chi dice “io dico d’esserci”, “io dico questo” è coglione due volte, prima perchè si ritiene io, secondo perchè è convinto di dire, è coglione una terza volta perchè è convinto di dire quel che pensa, perchè crede che quel che pensa non sian significanti, ma sian significati e che dipendano da lui.”
Chi invoca l’incapacità dell’artista di comprendere il senso di quello che fa, ricordandoci che le opere di un artista hanno valore solo come significanti, ovvero forma che finisce nella storia — una storia in cui il contesto cambia di continuo e così il modo di recepire l’arte — spesso porta l’esempio di Vincent Van Gogh.
La sua storia è presa ad emblema del fatto che la volontà dell’autore non conta, che nessuno è autore di niente visto che poi è la storia a decidere se quelle opere saranno o meno capolavori immortali. Siamo noi tutti a fare di Van Gogh un grande autore. Finché non abbiamo deciso altrimenti, le opere di Van Gogh erano inutili. Van Gogh è stato un pittore che ha venduto solo un quadro in vita sua, completamente incompreso, morto suicida e che è stato rivalutato molto tempo dopo la sua morte come uno dei più grandi pittori mai esistiti.
Per quanto è assolutamente vero che la mente di Van Gogh non poteva immaginare cosa sarebbe successo nella mente del suo pubblico, figuriamoci cosa sarebbe successo nella mente di un pubblico che non lo ha mai apprezzato dopo la sua morte (la fitta corrispondenza col fratello non lascia troppi dubbi in merito), resta il fatto che è stato comunque Van Gogh con il suo corpo a eseguire quelle opere e la sua mancanza di consapevolezza sul loro destino non lo priva certamente del suo ruolo di autore. La sua parte mentale vigile forse non era consapevole, ma è pur sempre la persona che fisicamente ha realizzato quei quadri. Credo che la separazione fra mente e corpo sia spesso involontaria ma assolutamente deleteria visto che viviamo in una società in cui significato e significante non sembrano essere più in una connessione inscindibile, in cui l’idea, la parola e la mente sembrano essere la sostanza dell’arte visiva, mentre il corpo e la forma poca cosa. Non è un caso che uno come Carmelo Bene, nonostante stia cercando di spiegare un concetto come quello riportato poco sopra citi alla lettera il pensiero di un altro uomo con un nome e un cognome, proprio perchè sa di essere costretto nei limiti dell’essere umano e proprio perché si affida all’arte come unica via di arrivare “ove non v’è più modo”.
Gli artisti sono mente e corpo che creano significanti, forma.
Capitolo 2
Conceptual art
L’arte concettuale è quell’arte in cui un concetto pensato dovrebbe essere l’elemento fondamentale dell’opera, nel tentativo di superare i limiti della materia dell’arte formale come è sempre stata intesa.
Considerando le opere ready-made di Duchamp, pioniere dell’arte concettuale, e concentrandoci in particolare sulla sua “Fontana”, un’opera basata sull’idea provocatoria di mettere un orinatoio in una galleria d’arte (che peraltro rifiutò di esporla), la relatività dell’importanza dell’aspetto formale e tecnico nell’arte sembrerebbe inquestionabile.
Dunque anche un umile orinatoio può assurgere a una dimensione artistica formale se l’artista concettuale lo sceglie come forma finale della sua opera. Infatti, nonostante adori Duchamp e tutta la sua produzione artistica, non reputo vero che il concetto abbia superato la forma, nel suo lavoro. Difficilmente troveremo opere visivamente più memorabili nella loro forma di quelle create da Duchamp, che sia la Gioconda con i baffi o la sua “Aria di Parigi”.
La forma, per casuale che potesse sembrare, e non lo era, è stata ironicamente la forza più grande di quelle opere: non sarebbe bastato declamare le idee che le hanno generate per fissarle nella storia dell’arte. Non sono rimaste solo ‘buoni concetti’; essi sono diventati splendide opere d’arte tangibili.
Hanno trovato una loro forma dall’immenso valore, anche economico — una forma tutt’altro che sostituibile da un’idea scritta o parlata. Non sono affatto dei segnaposto visivi per dei concetti scritti e ogni atomo della loro materia che le definisce è cardinale, nonostante si tratti spesso di un objet trouvé di cui è stato modificato un piccolo aspetto (la firma sull’orinatoio, l’allestimento a scultura di una ruota di bicicletta).
Riprova ne sia che la fontana di Duchamp è quell’oggetto lì e nessun altro orinatoio dello stesso modello.
Due galleristi di Maurizio Cattelan hanno vinto una causa importante contro lo scultore Daniel Druet. Druet chiedeva un rimborso di 6 milioni di euro in quanto il suo nome non è stato riportato come realizzatore materiale di due sculture famosissime di Cattelan, “Him” e “La Nona Ora”, nonostante fosse stato pagato per la sua prestazione da Cattelan che gliele aveva commissionate. Secondo il giudice che ha decretato inammissibile l’accusa di Druet, lo scultore non avrebbe mai avuto le competenze né le idee per poter ottenere le due opere in questione per quello che concerne l’allestimento e quindi dell’esperienza di fruizione del pubblico. Senza l’idea di Cattelan, in sostanza, le due opere non sarebbero mai esistite in quel determinato contesto di regia artistica, quindi non possono essere considerate anche sue:
“è indiscusso che le precise direttive per allestire le sculture di cera in una specifica configurazione, relative in particolare al loro posizionamento all’interno degli spazi espositivi volti a giocare sulle emozioni del pubblico (sorpresa, empatia , divertimento, repulsione, ecc.), sono state emanate solo da Maurizio Cattelan senza Daniel Druet, non essendo in alcun modo in grado – né cercando di farlo – di arrogarsi la minima partecipazione alle scelte relative alla disposizione scenografica della presentazione delle dette sculture (scelta dell’edificio e dimensione della le stanze che assecondano il carattere, la direzione dello sguardo, l’illuminazione, persino la distruzione di un tetto in vetro o di un pavimento in parquet per rendere l’allestimento più realistico e suggestivo) o al contenuto del possibile messaggio contenuto nell’allestimento”
Sebbene io concordi sul fatto che Druet ha accettato di lavorare sotto compenso, immagino cedendo ogni diritto di sfruttamento economico delle opere a fronte di una retribuzione immediata, l’affermazione che l’opera non sia sua per me è enorme e infinitamente meno scontata di quanto non la si voglia far apparire. Le due sculture hanno una forma inconfondibile che è frutto esclusivamente dell’opera di Druet, che è oltretutto uno scultore esperto.
Se le avesse scolpite un altro autore oggi avremmo due opere completamente diverse. Forma e contenuto non sono scindibili, inevitabilmente. Questo fa di Druet l’autore materiale e sostanziale delle due opere commissionate da Cattelan. Nessun committente può intestarsi la paternità di un’opera, neanche quando la modifichi (anche solo in piccolissima parte). I baffi sulla Gioconda di Duchamp sono disegnati su una riproduzione trovata per strada di quel quadro di Leonardo Da Vinci; quella stampa modificata ha un enorme valore per questa specifica combinazione di fattori. Se un contratto lo prevede, un artista che sfrutti il lavoro di un altro autore può acquisirne il diritto di sfruttamento commerciale; oppure può intestarsi, come nel caso di “Treasures from the Wreck of the Unbelievable” di Damien Hirst, l’autorità di una grande opera in cui tanti pezzi realizzati da terzi costituiscono parte di un disegno generale. Quest’opera “di Cattelan” quindi dovrebbe essere considerata un allestimento speciale per un’opera di Druet: ne stravolge il significato, portandola completamente altrove rispetto alle intenzioni originali dell’autore, ma resta una scultura di Druet usata in un progetto artistico di Cattelan.
Non può ovviamente dire: io ho fatto questa scultura, solo per aver avuto un’idea di come usarla poi.
Sei autore del modo di esporla, semmai, come si può ammirare nell’allestimento ormai celeberrimo dell’Ercole e Lica di Canova che si specchia nei “32 mq di mare circa“ di Pascali all’interno della mostra “Time Is Out Of Joint” curata da Cristiana Collu per la Galleria Nazionale Di Arte Moderna E Contemporanea.

“Time Is Out Of Joint” curata da Cristiana Collu
Syd Mead resta l’autore dello spinner di Blade Runner. Ridley Scott ha firmato il film, l’opera in cui lo spinner, commissionato da lui stesso a Mead, compare. L’opera “Fontana” di Marcel Duchamp ha un valore come operazione di linguaggio proprio perché Duchamp ha usato un semilavorato industriale generico, umile, popolare e lo ha firmato e allestito come fosse un capolavoro irripetibile, rovesciandone il significato e offrendo una esperienza al pubblico (solo potenziale, visto che non fu neanche mai esposto) completamente originale, operando cioè come un regista farebbe con la messa in scena in un film di un pezzo di creatività altrui — un grande gesto attoriale o un pezzo di scenografia. Non si è intestato l’orinatoio per quello che era. E proprio per questo credo anche che, come nel cinema, segnalare il nome del designer che ha progettato l’orinatoio non toglierebbe nulla all’opera del geniale artista francese, anzi.
«Se Mr. Mutt abbia fatto o no la fontana con le sue mani non ha importanza. Egli l'ha SCELTA. Ha preso un comune oggetto di vita, l'ha collocato in modo tale che un significato pratico scomparisse sotto il nuovo titolo e punto di vista; egli ha creato una nuova idea per l'oggetto.»
Lo Scrive Louise Norton, da “The Blind Man”, rivista Dada dove “Fontana” è apparsa per la prima volta.
Una “nuova idea” per “l’oggetto”.
Certo, si potrebbe obiettare che l’orinatoio scelto tutto sommato poteva essere uno qualunque, ma sarebbe come obiettare che la Gioconda avrebbe potuto essere bionda. L’orinatoio è quello là e non un altro. Solo questo conta, se vogliamo considerarla una vera opera d’arte e non solo l’idea di un’opera d’arte. “Fontana” non è fatta di spirito santo e anche se è stata replicata in più copie, sono tutte copie diverse, sono in un numero limitato e ognuna ha una dignità come opera che si riferisce al primo esemplare.
Proprio il cinema mi sembra che abbia risolto infatti questi tipi di problemi con un approccio decisamente semplice e trasparente: tutte le persone coinvolte in un’opera d’arte come un film sono riportate nei titoli di testa e coda. Non ci sono particolari opacità e non mi pare che ci sia nessuna lesa maestà nei confronti del/degli autori del film. Anche nell’editoria le persone che si sono occupate dell’editing, di stampare, di correggere le bozze compaiono nei credits dell’opera. Nessuno mi pare si permetterebbe di dire mai che una commissione o un brief delegittimino il lavoro specifico dei vari artisti e collaboratori coinvolti nella produzione.
Mi sembra che le altre arti dovrebbero imparare dal cinema.
Voglio precisare questa cosa perché spesso nei discorsi sull’arte, specie quella contemporanea, si crea una inutile confusione fra idea e cosa nella produzione di opere d’arte.
Nella discussione sulla AI art ho letto sui social media scambi di commenti come:
Utente A che commenta l’opera di un utente fruitore di AI text to image: “Non sono che un principiante eh: avere un’idea non è difficile, fare l’opera è difficile.”
Utente B, fruitore di AI text to image: “Ma no! Sono le idee ad essere merce rara, la tecnica invece si può sempre affinare è solo una questione di pratica. Tutta l’arte contemporanea dove la mettiamo sennò?”
Non esiste una separazione possibile fra forma e contenuto. Le idee nella mente dell’autore non sono mai il contenuto del significante. La forma che l’autore riesce a creare non è un segnaposto per le idee che ha in mente, è un significante che ha il suo significato. La forma è il contenuto, la forma è il significato dell’opera e non ha niente a che vedere con l’idea dell’autore. Le idee certamente ispirano un processo di semiosi visiva che produce un significante/significato. Rappresentare la grazia della Pietà di Michelangelo è una questione formale, non di idee. L’idea di una grandiosa rappresentazione di Dio non fa del Papa l’autore della Cappella Sistina. Buona parte dell’arte italiana è riassumibile in una manciata di idee noiosissime: sono spesso ritratti a mezzobusto, una dozzina di immagini sacre, sempre le stesse, paesaggi di campagna e poco altro. Quello che la rende unica non è la qualità delle idee, è la formalizzazione della visione. L’artista è chi crea il significante.
La Dama con l’Ermellino non è una idea formidabile, a parole. Ragazza nobile con un ermellino in braccio, fondo nero. Sui social siamo pieni di immagini di persone con il loro animaletto domestico. Scelte puramente visive non traducibili a parole, dalla forma delle ossa delle mani al colore usato per la pelliccia, sono elementi completamente ineffabili: pura semiosi visiva. È incredibilmente calzante in questo discorso la descrizione che sempre Carmelo Bene dà de “La Beata Ludovica Albertoni” del Bernini: “è prima delle parole, è dopo le parole, non appartiene più al discorso” (Maurizio Costanzo Show, Uno contro tutti).
Mi è stato obiettato che l’atto che crea la forma già in un'arte come la fotografia è ridotto al solo premere un bottone, cioè il gesto che porta alla fase di significazione formale si riduce a quello, e quindi è paragonabile al processo di generare un’immagine con una AI TTI commissionando al “genio nella macchina” un’immagine che mai sarei in grado di realizzare “direttamente”. Premere un bottone lo può fare chiunque, insomma, ed è un gesto che apparentemente è senza alcuna componente di autorialità intesa come controllo diretto sulla forma finale.
Fortunatamente sono cresciuto con un nonno fotografo semi-professionista e posso serenamente argomentare che ridurre lo scattare una foto a premere il bottone per il controllo dell’otturatore è purtroppo un modo molto limitato di intendere la fotografia. La fotografia è soprattutto framing, atto fisico di inquadrare la realtà da un punto di vista unico e irripetibile, scelta di cosa rappresentare e cosa escludere nel nostro scatto. È luce e capacità di comporre e previsualizzare: scegliere come illuminare un soggetto e come trattare la luce in relazione al dispositivo fotografico. È pianificazione e conoscenza degli strumenti per ottenere il massimo controllo formale nel momento cruciale, perchè non tornerà più. O, al contrario, è prendere un momento qualsiasi e usarlo come materia prima per un’immagine unica e irripetibile. È regia, rapporto umano, intimo o professionale che sia, con i soggetti e con la messa in scena. È empatia e comprensione della realtà. È scelta del supporto di visualizzazione, sviluppo e stampa. È post produzione di ogni tipo. È soprattutto contatto intimo con l’autore, che si muove nel mondo con il suo corpo e ci riporta le sue visioni. A pensarci bene, la fotografia è forse una delle arti più fisiche in assoluto in cui l’autore si fa parte costitutiva dell’opera d’arte, in cui i concetti di tecnica, visione e forma si incarnano nel tempo di uno scatto.
Siamo dunque lontanissimi da quello che succede con una AI text to image dove ci basta inserire del testo in un computer e stare a vedere che succede. Tenendo il paragone della fotografia, più che premere un bottone per ottenere un’immagine da un macchinetta fotografica, usare la AI TTI sembra più come mandare un pizzino dalla nostra cella all’Asinara a un fotografo (di cui non sappiamo nulla) e chiedergli di fotografarci “man standing window minimal living room zara home trending on domus lomography disposable camera moody”.
Un altro grande fraintendimento è nel paragonare le AI TTI a dei software con parametri numerici o con la possibilità di scrivere codice, di programmarli, solo perché si digita del testo per controllarli. Il fatto che in questi software si scriva del testo ― siano essi i parametri o la posizione nel tempo di un keyframe di animazione, uno script per ottenere un determinato shader, o i parametri numerici di un software di modellazione 3D — non toglie che queste siano tutte scelte che operano formalmente in maniera più immediata possibile sulla forma che viene rappresentata sul supporto scelto, e tutto ciò avviene in maniera intenzionale e formalmente prevedibile con un controllo digitale. Si tratta di strumenti per avere il maggior controllo possibile sulla forma finale, spesso preferiti alle interfacce naturali proprio per quello, e non certo per avere un controllo minore. Sono uno strumento privilegiato per usare il potenziale della macchina nella maniera più ampia possibile potendo arrivare a impostare manualmente i valori di ogni pixel di un’immagine, per esempio, cioè produrre forma nel modo più diretto possibile, toccando i bit come fossero interruttori fisici minuscoli a due posizioni su una pulsantiera sterminata.
Non è “dire alla macchina di fare”, è fare.
È controllo formale “low level”.
Tutto questo discorso mi richiama alla mente Peter Molydeux, un curioso personaggio a mio avviso degno di attenzione fra i milioni di account di twitter.
Peter scrive cose come:
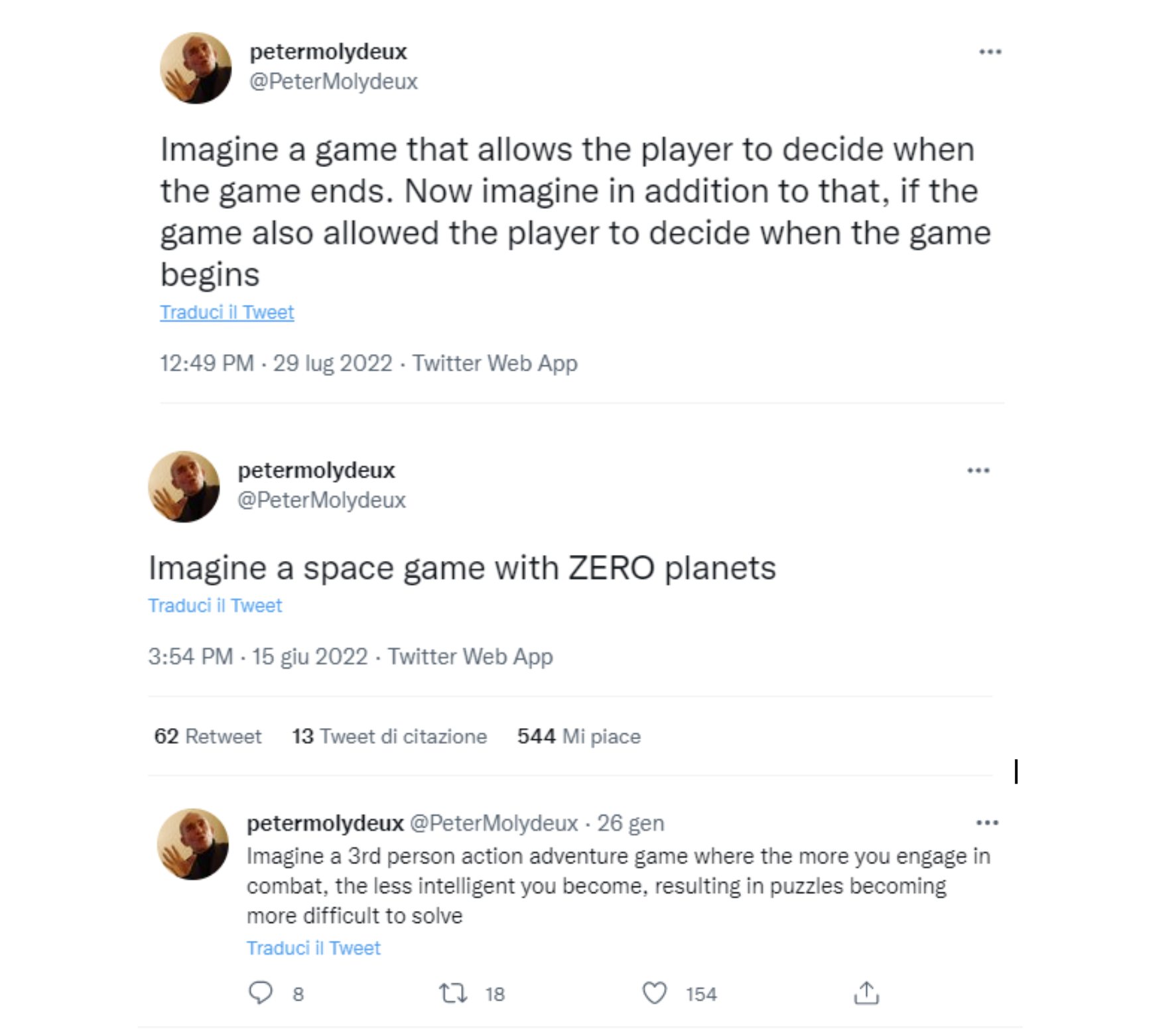
Si tratta di una parodia dei progetti insoliti di Peter Molyneux, un famosissimo game designer noto per la sua ossessione riguardo a originalità ed innovazione nei videogiochi. Molyneux è anche famoso per aver realizzato molti giochi dall’idea di partenza talmente interessante che non c’è mai stata realizzazione che abbia reso giustizia alle intenzioni. Molydeux sembra dirci: meglio avere una carriera di idee enunciate senza il problema di doverle realizzare davvero, perchè quello che resta e conta alla fine sono le opere, non le idee che le hanno ispirate - sempre che non ci si fermi alle sole idee.
Ovviamente la forma che Molydeux s’è scelto conta eccome, un tweet ha tutta una serie di elementi formali estremamente precisi che esaltano il concetto di sparata tranchant proprio per il numero di caratteri limitato, ma possiamo dire che rimanendo su un piano testuale (Molydeux non usa mai immagini) i suoi tweet sono sicuramente altamente concettuali e giocano con il principio di invenzione nel senso più astratto possibile, per provocare la creatività complice e spesso un po’ facilona dei suoi lettori.
Se potessimo ragionare fino a prova contraria o, meglio ancora, fino a una proof of concept, Molydeux sarebbe un genio del Game Design, prolifico come nessuno mai nella game industry.
Invece Peter Molyneux è un game designer di fama internazionale con un corpus di opere, mentre Peter Molydeux un brillante scrittore satirico di tweet per la nicchia degli entusiasti del game dev.
Capitolo 3
Text to image (and text)
Sono stato maleducato e non mi sono presentato.
Mi chiamo Lorenzo Ceccotti e disegno per vivere. Fra le attività che svolgo, la più importante è senza dubbio quella del fumettista.
Il fumetto è un medium visuale che usa immagini in sequenza come strumento narrativo.
Nelle immagini del fumetto, molto spesso, può comparire testo scritto in varie forme: dentro le didascalie, nei balloon, con integrazioni libere al disegno, onomatopee.



Gli spettacolari testi disegnati di “Spirit”, di Will Eisner.
Noi fumettisti quindi facciamo un lavoro speciale: ci esprimiamo con un medium convergente, in cui testo e immagine interagiscono di continuo. Il fumetto risolve i suoi quesiti espressivi con tutto l’arsenale della comunicazione visiva: testo, disegno in ogni stile immaginabile, disegno geometrico, impaginazione con tutte le relative tecniche del graphic design.
Testo e immagini comunicano in modi disparati e complessi anche durante la preproduzione del fumetto.
Non tutti i fumetti sono realizzati così, ma una parte di essi viene realizzata grazie alla collaborazione di più figure creative. Capita spesso che un fumetto venga scritto da una persona e disegnato da un’altra, dove per ‘scritto’ si intende sceneggiato e per ‘disegnato’ si intende illustrato, impaginato, colorato e letterato.
È molto interessante analizzare queste fasi del processo confrontandole con il discorso sulle intelligenze artificiali text to image.
La sceneggiatura nei fumetti è un testo che descrive a parole al disegnatore cosa ci deve essere disegnato nelle varie pagine del fumetto e include i dialoghi e le onomatopee.
Alcuni sceneggiatori usano una tecnica di scrittura che non fornisce alcuna informazione di regia né di scansione delle vignette, a meno che non sia strettamente necessario e comunque in una forma che non è mai nulla più di un consiglio:

Sceneggiatura e disegno di una pagina di “Ghost In The Shell - Star Gardens”, scritto da Brenden Fletcher e disegnato da me.
Altri invece operano con sceneggiature che riportano anche delle indicazioni di regia e informazioni sulla scansione delle vignette:

Sceneggiatura e disegno di una pagina di “Monolith - Secondo Tempo”, scritto da Roberto Recchioni e Mauro Uzzeo e disegnato da me.
In altri casi ancora la sceneggiatura riporta addirittura indicazioni sullo stile di disegno da utilizzare:

Sceneggiatura e disegno di una pagina di “Monolith - Secondo Tempo”, scritto da Roberto Recchioni e Mauro Uzzeo e disegnato da me.
In tutti i casi parliamo di testo, un prompt fatto di parole — alle volte in un particolare linguaggio specializzato, alle volte no — che si traduce in sequenze di immagini e testo per mano del disegnatore.
Del lavoro dello sceneggiatore, l’unica parte che arriva a impattare direttamente sulla forma della tavola definitiva è il testo dei fumetti e delle didascalie, che viene comunque rappresentato dal disegnatore (o da un letterista) con il lettering: è quindi comunque in mano a un artista visuale che si occuperà di sceglierne la forma. Nel fumetto il testo può essere infatti rappresentato in una infinità di modi; ogni modo di rappresentarlo — la diversa grafia, il posizionamento, la dimensione…— ne cambia considerevolmente il significato.


Nei fumetti la stessa parola, se scritta in un modo grafico diverso rispetto a un altro, può assumere significati diversi. La forma grafica del testo è significante quanto il testo stesso ed è una parte colossale del sistema espressivo del fumetto. Il testo dei fumetti non funziona come nei libri di sole parole o nelle didascalie dei libri illustrati.
Illuminante in tal senso è il volume "Gli Ultimi Giorni Di Pompeo" edito da Union, dove sono stati rimossi i disegni per lasciare il solo testo manoscritto da Pazienza. Sebbene questo libro sia stato frainteso come un modo di dire: “guardate che bel testo, Pompeo: è un capolavoro più letterario che grafico” e abbia fatto innervosire moltissimi fumettisti italiani io la trovo la più grande dimostrazione del peso che ha la grafica nella rappresentazione del testo nei fumetti.


Gli ultimi giorni di Pompeo, Union editions.
A vederlo così, da solo, è autoevidente come il testo sia una questione assolutamente visuale nel fumetto; fa riflettere che l’uso del testo così libero latiti dai fumetti scritti da uno sceneggiatore che non ne sia anche il disegnatore. Per contro, il fumetto può essere anche completamente muto:

“Gon” di Masashi Tanaka
— e raccontarci comunque storie, come quelle che racconta Masashi Tanaka con il suo “Gon”. Tanaka rompe la barriera della parola Giapponese creando il primo caso di un Manga che nasce universalmente comprensibile da tutti i lettori di fumetti dal mondo.
Il fumetto, esattamente come tutta l’arte figurativa, si presenta in una forma visibile, su un supporto. Spesso il supporto è un libro, un libro può avere anche moltissimo testo in sequenza, ma che va sempre e comunque considerato opera visiva in cui la trama detta a parole non ha alcun valore in sè. Solo la forma che di fatto assume nell’opera ad avere valore. Non esiste storia che garantisca la forma di un fumetto eccellente, così come nel cinema esistono capolavori letterari adattati in film mediocri e film indimenticabili tratti da libri insulsi. Possiamo raccontare la storia più banale del mondo, “un uomo che passeggia nel bosco contemplando le meraviglie della natura” e farlo in maniera eccezionale, creando una storia che verrà ricordata per sempre senza che neanche una sola parola finisca sul foglio. Come invece potremmo prendere la migliore sceneggiatura di Alan Moore, un grandissimo sceneggiatore di fumetti, e disegnarla talmente male da renderla insopportabile.
Non intendo dire che il fumetto sia una questione di bel disegno, anzi — nulla di più sbagliato: intendo dire che la forma (sia essa pazza e strampalata o un florilegio di soluzioni tecniche virtuosissime) è ciò che costituisce l’opera, e come in ogni medium visuale sarà l’aspetto visivo a definire la qualità dell’opera, non il suo progetto scritto.
Non voglio dire neanche che il lavoro di uno sceneggiatore non sia importante: lo è come è importante un soggetto per un grande pittore di figura.
Moltissimi personaggi della storia dell’arte si sono scelti i loro ritrattisti e lo hanno fatto con cura e attenzione perché avevano a mente il tipo di risultato che volevano ottenere, ma nessuno dei soggetti ritratti si intesterebbe mai la paternità dell’opera.
Da sceneggiatore, quando ho scritto un testo per un disegnatore mi sono trovato nella situazione di scrivere una storia con una chiara visione di come avrei disegnato io quelle tavole: nel momento in cui le ho ricevute dal disegnatore le tavole erano ovviamente diversissime da quelle che avevo in mente e mi hanno sorpreso proprio per quello e per la loro complessità e bellezza. Mai mi sarebbe mai passato per la testa il fatto che io fossi autore di quelle pagine, era chiaramente il disegnatore. Io avevo solo scritto un testo; ero l’autore della sceneggiatura, non del fumetto.
Lo stesso vale per quanto riguarda uno sceneggiatore di cinema. Lo sceneggiatore scrive un testo che opera come mappa della storia e dei dialoghi del film, ma la reggenza (o regia) di tutta la performance attoriale e delle maestranze ha una tale importanza sul risultato finale che non può che avere il massimo grado di considerazione sulla paternità del film. Per fare un esempio ancora più eclatante: nell’opera lirica l’autore della musica non è l’autore del libretto. E la performance è opera di un altro autore ancora che può assolutamente stravolgere il significato di musica e libretto con la sua messa in scena: si prenda ad esempio la Carmen di Georges Bizet e la sua originale messa in scena firmata dalla regista Valentina Carrasco per la direzione di Jordi Bernàcer. Si tratta di opere diversissime fra loro e che hanno ognuna il suo autore e il suo significante/significato.
Un’ultima nota sull’argomento è fondamentale per comprendere ancora meglio la nota di Peter Greenaway cui mi riferivo prima sulla cultura visuale segregata dalla parola scritta: tutto quello che ho scritto sopra non va molto d’accordo con il mondo industriale, me ne rendo conto e non penso che sia una cosa contro cui abbia molto senso lottare. È così e basta. Infatti è ovvio che sia molto più semplice dal punto di vista logistico affidare la paternità di un qualsiasi prodotto visivo seriale a uno scrittore piuttosto che a un artista visivo e il motivo è che gli autori di arte visiva, siano essi registi o disegnatori, sono spesso lentissimi. Ciò non cambia una virgola di quanto detto prima sul piano artistico e filosofico ― è solo che tra il dire e il fare c’è di mezzo il mare e fra scrivere e disegnare c’è di mezzo un mare di tempo. Per garantire una frequenza utile su un piano di uscite è di vitale importanza la figura di un autore che assuma la funzione di showrunner, che tenga le redini del lavoro nel suo insieme per più tempo possibile. Non è un caso che in Italia, ad esempio, gli autori che disegnano e che hanno una enorme produttività tale da riuscire a sostenere il ritmo produttivo siano quelli che hanno un altissimo livello di stilizzazione grafica (Maicol&Mirco, Sio, Dr.Pira, Fumettibrutti ecc.); e non è neanche un caso che il paese dove accade il contrario sia il Giappone, dove un artista visivo ad alta intensità grafica può tenere un ritmo incredibile grazie a budget produttivi e un’industria non paragonabili a quelli occidentali, aprendo alla possibilità di poter usufruire di studi interi di assistenti specializzati nello snellire la pipeline produttiva dei mangaka. Questa strategia operativa pone gli artisti visivi preverbali ad alta intensità formale nella posizione peggiore possibile rispetto ai loro colleghi che lavorano con le parole, e lo fa in una maniera pervasiva e subdola anche in moltissimi aspetti corollari.
Vi faccio un esempio sul mio vissuto artistico: sempre parlando di fumetto, il fatto che spesso finisca su un supporto libro crea un ulteriore problema concettuale.
I libri sono un medium che statisticamente è da sempre associato alla parola, tant’è che ci sono voluti anni perché i libri a fumetti riuscissero a farsi strada nelle librerie di varia. Ed è stato un processo lungo e complicato che ha alla base una distinzione correttissima a mio avviso: scrittura e fumetto sono due medium completamente diversi. Generalmente chi scrive critica di fumetto per la costellazione di siti specializzati che formano la “stampa di settore” non è un autore di fumetto, tantomeno un artista visuale. Non è neanche un professionista della scrittura, sono pochissimi a riuscire a vivere del loro lavoro di critici del fumetto. Sicuramente scrive di fumetto perché ama leggere, ha un percorso umanistico letterario, legge anche molti fumetti,e soprattutto perché sa scrivere. Con un bagaglio culturale di questo tipo è inevitabile che leggerà i libri a fumetti con quello che chiameremo un “bias letterario”, ovvero una predisposizione all’aspetto testuale del fumetto.
La trama quindi assume un valore completamente sproporzionato ed idealizzato rispetto alla forma finale dell’opera. I disegni sono spesso analizzati e liquidati in un frase della recensione e poco più, senza alcun approfondimento sulle scelte formali che non influiscono direttamente sul racconto dell’intreccio. I disegni quindi saranno “belli” o “brutti”, “sciatti” o “spettacolari”, “delle vere opere d’arte” come fossero un elemento a parte rispetto all’opera, come se illustrassero il testo; difficilmente avremo un’analisi della composizione, del ritmo della sequenza, delle scelte rappresentative (tipo di sintesi, recitazione, rapporto di significazione fra figura e sfondo, analisi delle scelte tecniche e del rapporto con l’esperienza di lettura, la poetica visiva, l’analisi del framing, la stabilità stilistica, il montaggio, il graphic design per l’integrazione di immagini testo e gabbia, il rapporto con l’immaginario collettivo e la cultura dell’immagine e chi ne ha più ne metta). Soprattutto il più delle volte avremo un giudizio, e non un’analisi. Sulla trama e i dialoghi invece ci si addentra più facilmente proprio perché attiene all’ambito di competenza di chi scrive e questo rende la vita di un artista visivo come un fumettista veramente difficile. Fra fumettisti il modo più facile per orientarsi sulla qualità del proprio lavoro diventa quindi parlarne con altri colleghi, oppure di provare a cercare fra i pareri dei lettori casuali.
Tutto questo per dire che il feedback della critica è perlopiù di carattere letterario, purtroppo, come se i romanzi venissero tutti giudicati da espertissimi graphic designers per il loro lettering, per l’impaginazione, per la copertina, l’aspetto cartotecnico e solo di passaggio se ne analizzasse il testo vero e proprio. E questo è solo un esempio di quanto la parola scritta spesso si sostituisca alle immagini nel processo di comprensione di un’opera visuale.
I primi fumetti che ho visto realizzati con delle AI text to image soffrono esattamente di questo limite semiotico visivo, sono commissionati da chi scrive come se il disegno fosse un di più, come se la creazione di un fumetto si limitasse ad accostare una immagine al testo che si è scritto per cercare un bell’accostamento, cercando di accostare il testo a della “bella roba”. E, se vogliamo essere ancora più pignoli, sono tutti fumetti in cui il testo non sta compositivamente dove dovrebbe stare, non è rappresentato graficamente con competenza, non produce un'autentica interazione sequenziale con le immagini. Ribatte invece il contenuto delle immagini come fosse una didascalia per non vedenti (“mi sento solo”, di fronte a un omino solo nel deserto, “mi trovavo nel bosco” e c’è un omino nel bosco, “aprii la porta” e c’è un omino che apre una porta) o prova a confortare l’autore di essere in controllo, come se con il testo si cercasse a tutti i costi di nascondere la casualità delle immagini creando un effetto davvero artificiale che rende la lettura insopportabile.
Fa sorridere che il più delle volte gli autori di questi fumetti scrivano cose tipo:
”ho dovuto battere il prompt per 40 volte per ottenere questo omino che apre la porta, purtroppo le AI non sono un granché a disegnare le interazioni”
come se il problema fosse quello, e non che si preferisca attivare server incredibili dall’altra parte del mondo, a pagamento, e farlo per 40 volte invece di prendere una matita e sforzarsi di disegnare una porta, quella preziosissima porta che hai in mente (e che magari non è neanche detto sia davvero una scelta interessante). La mancanza di proprietà di linguaggio visivo di questi primi esperimenti di autori che non vengono dall’arte sequenziale o comunque con una scarsa competenza visiva risalta con una maggiore veemenza proprio perché ora stiamo assistendo a una corsa forsennata per essere tra i primi a pubblicare storie “realizzate” con questa nuova “tecnica”. “Sperimentale”.
Invece che pionieri e sperimentatori sembrano più carne da cannone, early adopter in fila per il nuovo iPhone. Vediamo cosa dirà la critica, ma ho uno strano, pessimo presentimento.
Capitolo 4
Tra il dire e il fare
L’arte visiva è quindi fondata, come dicevamo, sulla forma delle immagini prodotte dall’artista, certamente non sui concetti o i percorsi che possono aver guidato l’autore o sulle sue fonti di ispirazione, siano esse reali o astratte. Alla fine del processo creativo resta solo la forma finale dell’opera, certamente inserita in un contesto culturale in continua evoluzione, ma inequivocabilmente quella.
Prendi lo stesso concetto scritto e forniscilo a 10 artisti visivi diversi: avrai 10 opere visive diverse, che partono da 10 visioni diverse.
Per lo stesso motivo nessuno che scriva un brief via email a un artista visivo avrebbe mai il coraggio di arrogarsi l’autorità dell’immagine finita. Puoi arrogarti l’autorità del testo che ha ispirato l’opera, ma non dell’opera, visto che sono due cose completamente diverse. Il brief è poco più di una fonte di ispirazione verbale che non ha nessun controllo reale sulla forma dell’immagine.
Scrivere a Leonardo Da Vinci di realizzare un ritratto a olio di una giovane donna sui vent’anni, con i capelli lunghi e castani e lo sguardo enigmatico, davanti alle colline toscane che si perdono nei colori del cielo nello stile del Verrocchio non ci mette nella condizione di sentirci autori in nessun modo della Gioconda. Non c’è nessuna parola in grado di descrivere le forme che Leonardo ha infine scelto e dipinto per mostrare al mondo la sua visione. Non c’è un solo giro di parole che possa descrivere la curvatura dei polsi, quella posa così specifica delle mani, le qualità della sua pelle, la forma dei suoi occhi, il modo in cui il volto si contrae leggermente per abbozzare il suo sorriso. La forma finale dell’opera è visiva, tutto il resto, ispirazione scritta o visiva è un viatico che può essere dimenticato (se non a fini puramente storiografici).
Provo a esemplificare ulteriormente usando una situazione nota a tutti e ancora più radicale: poniamo un modello su uno sgabello in mezzo a una stanza e invitiamo 15 pittori a ritrarlo. Avremo 15 opere completamente diverse. Senza il modello avrebbero potuto realizzare il quadro? No. Eppure mai e poi mai il modello si sentirebbe autore o coautore di alcun quadro. Questa cosa resta vera nonostante si tratti di una traduzione da visivo (la visione del modello in carne ed ossa) a visivo (l’opera), figuriamoci se non lo è per un testo.
La visione di un artista viene trasferita da un’immagine mentale a una nuova immagine fisica, esperibile da tutti, e questo succede con tutti gli impedimenti tecnici del caso creando una incredibile varietà di risultati: dagli incidenti disastrosi a quelli felici, anche quando un’opera è soddisfacente per l’artista è sempre un compromesso fra l’attrito della mente col corpo.
Proprio per questo sento parlare delle AI text to image come un nuovo strumento ottimo per i concept visual artist perchè ridurrebbe buona parte di questo attrito. Uno strumento così perfetto che potrebbe addirittura minacciare di soppiantare i professionisti lungo le pipeline produttive del cinema riducendone le opportunità di lavoro.
Capitolo 5
Conceptual Visual Art
La concept art, versione breve per conceptual visual art, ha un nome facile da fraintendere con un’arte che prende concetti scritti (il brief) e li trasforma in arte visiva. Nulla di così sbagliato. La visual concept art è una forma di speculazione puramente visiva, che prende ispirazione da un brief per sviluppare un concetto visivo originale, permettendo ad altri di visualizzare immagini più vicine possibili a quelle nella mente dell’artista autore del brief, e non le parole del brief.
Facciamo un esempio: poniamo che per un film io debba creare la concept art di una location che deve offrire tutta una serie di opportunità narrative specificate nel brief. Ispirato dall’opportunità, ho questa visione di un luogo incredibile, che ha tutta una serie di caratteristiche estremamente specifiche, caratteristiche che sono il mio obiettivo figurativo visto che mi creano tutta una serie di reazioni emotive molto forti e che mi sembrano fare al caso mio.
Ora si tratta di riversare questa immagine unica su un supporto visivo.
Quando mi siedo al tavolo da disegno o al computer, la sfida è proprio cercare di visualizzare l’ineffabile, quell’immagine lì e nessun altra. Ovviamente non si tratta sempre di una immagine completamente chiara in tutti i suoi dettagli, si tratta di un sistema di informazioni visive che una volta formalizzate mi permettono di scendere ulteriormente nel dettaglio. Molto del lavoro di immaginazione si sviluppa mentre disegno, senza dubbio, ma resta dall’inizio alla fine un processo visivo.
Poniamo che voglia realizzarla con una AI text to image. All’inizio già ho un problema: non posso trasferire le informazioni da visivo a visivo. Da visione a disegno. Impossibile. Anche quando una AI sarà talmente veloce e sofisticata da permettermi di intervenire mentre lavora, magari intervenendo con un tablet o conversando con lei, dovrò comunque passare per un sistema che usi una forma rudimentale di note grafiche o a parole e le parole non hanno niente a che fare con la visione, se non nella loro forma grafica.
Per la precisione, qui parliamo di parola pensata, prima ancora che scritta. Posso quindi provare a descrivere la visione alla AI e letteralmente tirare a sorte una volta, e un’altra volta ancora. All’infinito. Posso aumentare il numero di elementi su cui approssimare, ma è puramente una questione statistica.
Nella migliore delle ipotesi, a forza di descrivere la visione troverò delle immagini che possono ricordarla, come se stessi descrivendo il volto del mio aggressore a un instancabile artista degli identikit.. Nonostante gli infiniti tentativi non potrà che dargli una forma sommaria, che gli somiglia forse alla lontana. Posso anche mostrargli delle immagini di altri che secondo me gli somigliano per aiutarlo ad avvicinarsi, ma mai riuscirò a fargli disegnare quello che ho in mente davvero, quell’espressione che mi ha terrorizzato. Il paradosso è che più il volto dell’aggressore mi è rimasto impresso nella memoria, tanto più ne ho una visione chiara e inconfondibile, tanto più dovrò accontentarmi e convivere con l’idea che la mia visione resterà per sempre dentro di me, sperando che l’identikit sia simile quanto basta.
Finché non accetto l’approssimazione ci troveremmo davanti al tipico caso di micro management del committente frustrato sull’artista, un grande classico del mondo dell’arte.
La peggiore delle ipotesi invece è che potrei rimanere estasiato dal risultato, ma non per aderenza al quesito visivo iniziale, quanto per una qualità formale che io non sarei mai in grado di raggiungere: il piano cambia, la visione originale non conta più, mi dimentico del mio assassino e mi innamoro di questo volto stupendo che mi ha disegnato un incredibile artista alla stazione di polizia. Davvero una sorpresa, mai mi sarei aspettato che un poliziotto potesse disegnare labbra tanto sublimi. Il giorno dopo il poliziotto muore in uno scontro a fuoco. Il disegno è a casa mia. Nessuno sa che non lo ho disegnato io. Sai che c’è: questo identikit è un capolavoro, lo incornicio, gli trovo un bel nome catchy e lo rivendo a nome mio.
Il caso del coinvolgimento di Hans Ruedi Giger nella produzione di Alien è emblematico di questa particolare casistica.
Ridley Scott era un eccellente disegnatore, un fanatico della 2000AD e degli Humanoïdes Associés con una spruzzata di quell’immaginario sci-fi americano verosimile che aveva fatto grande Star Wars. Oscillava fra la linea chiara nervosa del fumetto brit e quella elegante del fumetto francese, con una passione per le strutture meccaniche ritmiche e le campiture a marker prese in prestito dal visualizing tecnico dei designer di prodotto.


Era quindi assolutamente in grado di disegnare le sue idee, e infatti buona parte degli storyboard di preproduzione sono di suo pugno. Nonostante questo Scott capì che le sue idee erano ottime a parole, ma non erano davvero interessanti, formalmente. Aveva bisogno di un’altro livello di qualità per le sue immagini e incaricò Ron Cobb di occuparsi di formalizzare l’immaginario del film. Ron Cobb, il primo visual concept designer di Alien, fu chiamato proprio per le sue doti da vero industrial designer, per fornire un apporto sulla falsariga di Ralph McQuarrie su Star Wars, il grande evento cinematografico su cui Alien cercava disperatamente di mettersi in scia.
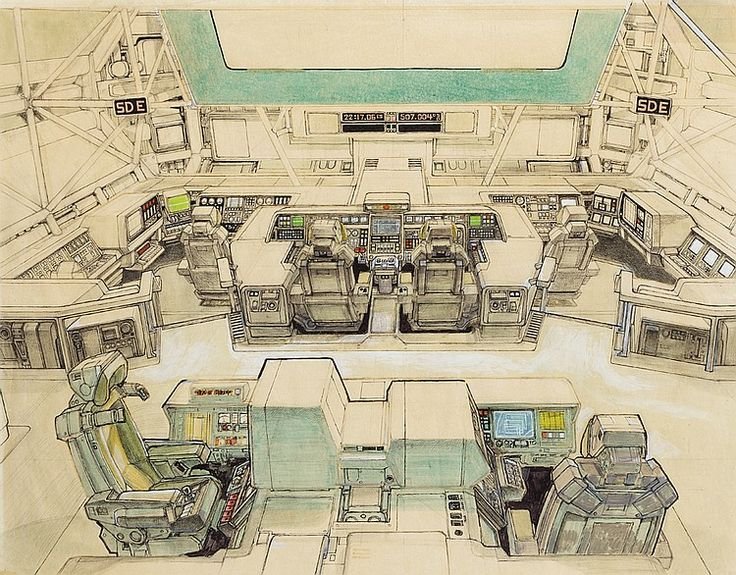


Il suo rigore formale e la sua visione traspaiono in ogni ambito della fantascienza “umana” nel film, in oggetti e strutture che Ridley Scott avrebbe potuto visualizzare a modo suo arrivando però ad un immaginario estremamente meno approfondito e originale, e che Ron Cobb portò invece alla luce con una mole di idee visive e un livello di dettaglio che resero le ambientazioni di Alien inarrivabili e probabilmente le più imitate della storia del cinema di fantascienza. Per quanto il brief potesse essere dettagliato, Scott non sarebbe semplicemente mai stato in grado di visualizzare tutta quella mole di soluzioni nella sua mente.
Una situazione davvero inaspettata si verificò però nel processo di formalizzazione dell’alieno.


Uno dei riferimenti principali per il film di Scott era Dark Star, il film di diploma di John Carpenter. In Dark Star c’è questa figura aliena piuttosto ridicola, una specie di pallone gonfiabile con dei piedi di papera. Cobb disegnò un alieno che era poco più di una specie di crostaceo su due zampe per nulla spaventoso e per quanto Scott stesse già sviluppando il film con al centro quell’idea visiva di buffo alieno tutto cambiò quando proprio Dan O’ Bannon, l’autore dell’alieno di Dark Star e arruolato nel cast tecnico di Alien proprio per quello mostrò a Scott un libro. Era “Necronomicon” pubblicato da Sphinx Verlag nel 1977 e comprato presso la mostra parigina dell’autore, un oscuro pittore svizzero, Hans Ruedi Giger. Scott è scioccato dall’immaginario di Giger, ma è un’immagine del libro a pagina 65 intitolata NECRONOM IV che rappresenta una creatura dalla testa oblunga, esplicitamente fallica, a sconvolgerlo definitivamente: l’alieno doveva essere fatto così.

Necronom IV
Scott non sente storie e nonostante tutta una serie di difficoltà logistiche (Giger non ne voleva sapere di viaggiare in aereo) commissiona al pittore svizzero una serie di immagini per visualizzare meglio l’alieno in tutti i suoi stadi evolutivi. Il resto è storia e il film diventa indimenticabile proprio per questo clash di visioni contrapposte: da una parte la visione razionale, terrena, sistematica, strumentale, quasi positivista della tecnologia di Ron Cobb a rappresentare la razza umana, dall’altra l’organicità spaventosamente ritmica, occulta, ipersessuale, buia e recondita della natura orrorifica e leopardianamente amorale dell’immaginario di Giger.

Ron Cobb e Hans Ruedi Giger durante la lavorazione di Alien.
Giger, quindi, non fu scritturato per disegnare una creatura da zero. Fu in primo luogo chiamato per poter usare NECRONOM IV, opportunamente corretta per renderla compatibile con gli standard di censura cinematografici, e per portare tutta la troupe del film nel suo oscuro mondo che prenderà il nome di “Acheron”. Fu chiamato come medium verso uno specifico immaginario che era già dentro la sua testa.

Lo Xenomorfo nel suo design definitivo.
Ridley Scott, il committente e autore del film, lo ha chiamato a collaborare perché solo Giger sapeva che aspetto avrebbe avuto Acheron e lo Xenomorfo — come un esploratore coloniale che si procuri le sue visioni facendosi guidare da uno sciamano esperto di terre sconosciute.
La visione allestita da Giger ha irreversibilmente contaminato il suo immaginario e di conseguenza quello di migliaia di di artisti, ridefinendo l’immaginario per ‘mondo alieno’, e lo ha fatto con le immagini: non con le parole, ma con una visione.
Giger, per questo, è diventato di diritto uno dei più grandi concept artist per il cinema mai esistiti, anche se di fatto non ha mai dovuto sviluppare su commissione un immaginario veramente da zero. Ha organizzato una scampagnata in una parte della sua mente per vedere se ci fosse qualcosa di buono per quello strano b movie.
Il risultato è entrato nella storia.
Capitolo 6
Divinazione on demand
Sebbene le AI siano già utilizzate nella produzione di film e videogiochi questo non ci dice nulla sulla reale bontà e utilità del processo. Ha senso dire che le AI sono un ottimo sistema per la produzione di conceptual visual art? Personalmente credo di no, e anzi temo sia un pratica che andrebbe fortemente scoraggiata per una serie di motivi molto semplici.
Le AI comunicano con noi con un linguaggio naturale, sia a parole (con un prompt testuale) sia tramite una serie di indicazioni di disegno elementare. La connessione parola-immagine è completamente arbitraria già negli spettatori dell’arte tradizionale; nel caso delle AI questo è ancora più estremo, perché capita nella fase creativa e non nella fase di esperienza dell’opera finita. Inoltre l’inserimento di un prompt produce una fase, rilevante seppur breve, di riprogrammazione mentale dell’utente, un po’ come accade fra committente e artista quando avviene la consegna del lavoro per l’approvazione: il committente chiede una cosa a parole o anche con delle reference, l’artista fa una cosa che risponde alla richiesta a parole del committente, gira attorno alle reference evitando ogni forma di plagio, produce un’immagine che è comunque completamente diversa dall’immagine mentale del committente e che pone il committente davanti a un quesito cruciale. Può farsi riprogrammare la mente dal risultato, vedere il risultato come un’opportunità utile al suo scopo. Convincersi, insomma, che è proprio quella l’immagine giusta. Può aiutare, in particolare, il fatto che l’artista abbia una reputazione grande o che abbia una documentazione del lavoro importante alle spalle. Come accade con la lettura dei tarocchi, la grandezza di un cartomante non è quella di riuscire a scoprire veramente qual’è il significato di quelle carte sul tavolo quanto quella di convincerti che quelle sono le tue carte, che dietro quelle carte si cela la tua storia, con la differenza che il processo di un artista non è casuale come l’estrazione di alcune carte dal un mazzo: c’è un percorso preciso e più è organizzato più il destino sembra già segnato.
Nel caso che si decida di andare per questa prima strada, è quantomai evidente che il committente si adegua alle scelte dell’artista.
L’alternativa è rifiutare l’immagine, perfezionare il brief segnalando quello che non va, insistere e riprovare ancora una volta, aggiustare il tiro, sperando di raggiungere una soluzione migliore, magari segnalando all’artista anche con delle note visive e con nuove reference cosa vorremmo vedere nell’immagine. Il risultato di un secondo o anche terzo passaggio ci porterà, in base alla flessibilità dell’artista, verso nuove opere che possono soddisfare maggiormente, ma che resteranno sempre forme originali dell’artista, mai di proprietà intellettuale del committente.
Anche in questo caso non esiste alcuna forma di autorialità da parte del committente. Si può essere solo più pignoli, meno pignoli, sentirsi più in controllo del progetto. Ma mai, in nessun caso, il committente può sentirsi autore dell’immagine.
Tanto è vero che se l’artista a metà lavoro dovesse decidere di abbandonare l’impresa il committente si ritroverebbe con un pugno di mosche.
In questo senso mi ha molto colpito come funziona la legge davanti al mandante di un omicidio e all’esecutore materiale: il mandante, l’ideatore del colpo, se la può cavare con 20 anni di galera, ma è l’esecutore materiale a venire condannato all’ergastolo. Infatti l’esecutore può rifiutarsi di portare a termine il suo compito, può salvare la vittima cambiando idea, può denunciare il mandante e soprattutto è quello che davanti alla vittima non ha avuto nessuna pietà.
Un utente di una AI text to image andrebbe serenamente inquadrato come il mandante, un committente che può chiedere a parole quante proposte creative vuole, dando quante reference vuole a un instancabile artista artificiale e che spesso paga per i suoi servigi.
Per complicato che possa essere un prompt non sarà mai, epistemologicamente, una fase di produzione di immagini, ma una commissione con un possibile scambio di denaro per ottenere un risultato libero da diritti commerciali pendenti, esattamente come lo è una email in cui io, artista umano, ricevo un brief di progetto per un’illustrazione a pagamento. Per dettagliato che possa essere, , per quanti incontri si siano rivelati necessari per parlarne assieme, per quante correzioni mi siano state fatte per arrivare al risultato finale, nessun editor o autore di libro si è mai sognato di intestarsi le mie illustrazioni
Le immagini sono mie. Nella presentazione del lavoro scriverò chi è stato il mio committente/cliente, se ce n’è stato uno. Se c’è stata un’agenzia, un direttore creativo e quant’altro. Ma nessuno potrà mai contestare che la paternità intellettuale dell’immagine è la mia e mia soltanto (che non ha nulla a che vedere con i diritti di sfruttamento commerciale che possono invece essere ceduti anche a tempo indeterminato).
Quindi anche nel caso di una AI text to image le immagini sono incontestabilmente della AI, ovvero della società proprietaria della AI.
L’utente di una AI text to image as a service di entità terze, specialmente se non è neanche a capo della curatela dei dataset, non può mai in nessun caso venire considerato l'artista visuale autore delle immagini ottenute.
È l’AI a produrre l’immagine operando il processo di semiosi visiva. L’AI non sa nulla della nostra visione mentale, qualora ce ne fosse una. Volendo essere molto generosi, vista la genericità assoluta dei prompt rispetto alla complessità del risultato, l’utente può essere al limite il soggettista, l’editor, il curatore, la fonte di ispirazione, qualsiasi dicitura si voglia dargli, ma non può essere in nessun modo considerato autore dell’immagine, perchè l’immagine non l’ha mai pensata, non sa nulla dell’immagine, può solo fruirne come cliente spettatore e eventualmente sceglierla per usarla in un libro, esattamente come succede con la fotografia stock, ma senza la spiacevole sensazione che potrebbe venire usata da qualcun altro, visto che la AI genera immagini diverse per ogni prompt.
“Ecco una nuova immagine estratta dalla mia mente grazie a questa nuova tecnologia incredibile delle AI text to image”
Così commenta sui social un utente che mai aveva disegnato prima, sotto a un’immagine pittorica spettacolare postata sul suo profilo.
“sto ancora lavorando a queste immagini, ma sono a buon punto, credo di aver trovato la ricetta giusta”
“questa AI offre risultati più sognanti delle altre”
“sto sperimentando” / “ecco altri esperimenti”
“Estrarre”, “sognare”, “lavorare”, “creare le ricette”, “cibare”, tutto il linguaggio che ruota attorno alle AI sembra essere votato al convincersi che quello che si sta facendo sia altro.
Per non parlare del concetto di “sperimentazione” che è completamente stravolto.
Sembra la logica con cui le grandi corp dei social network hanno provato a squattare con la forza termini come “amicizia”, “condivisione”, “comunità” per camuffare delle squallide operazioni per acquisire contatti commerciali, con la differenza che qua sono i clienti a voler tradire il linguaggio, spontaneamente — credo per una strana forma di pudore rispetto al fatto di pavoneggiarsi sui social per il lavoro di una macchina situata chissà dove, che per due spicci ci ha prodotto un’immagine originale della quale non verrà mai a chiederci conto e che non saremmo mai stati in grado di pensare per conto nostro.
È talmente evidente che l’immagine non sia dell’utente e che non sia mai stata neanche per un istante nella sua mente che bisogna essere completamente privi di consapevolezza visiva per pensare il contrario o che l’immagine sia legata in qualche modo alla nostra volontà, o peggio ancora che tutto quello che riempie l’immagine che non sia strettamente rimandabile alle parole del prompt sia una sorta di conseguenza ovvia di quelle specifiche parole, un precipitato scontato di una premessa, per vaga che possa essere.
Se pensiamo alle sterminate possibilità di rappresentazione di un essere umano è assolutamente patetico pensare che proprio quello che ci ha offerto un software ad approccio stocastico possa davvero essere quello che stavamo pensando, è una possibilità in un numero di avogadro di numeri di avogadro di casi (ok è un’iperbole, ma mi serviva rendere l’idea).

Stable Diffusion, 6 risultati diversi per lo stesso prompt: “woman”.
Su Stable Diffusion, ho inserito 6 volte un prompt semplicissimo e banale: “woman”. Tralasciando se le immagini siano soddisfacenti o meno, non è questo il punto dell’esperimento, possiamo invece constatare una serie di cose estremamente interessanti. Prima di tutto c’è una scelta formale costante: sono tutti primi piani. A differenza del prompt, il risultato è scelta tutt’altro che banale, una roba enorme dal punto di vista artistico e completamente non richiesta. Inoltre le 6 immagini hanno stili grafici diversissimi fra loro tanto che non hanno davvero nulla a che fare una con l’altra. Scegliere un’immagine fra queste per poi poter dire “ecco questa è una mia opera visiva” è la cosa più lontana da un atto creativo visuale che mi possa venire in mente, una pazzia.
È una pazzia, come pensare che ogni piccola escrescenza e imperfezione dei corpi di Egon Schiele siano stati anche solo per un istante parole nella testa dell’artista.

Quattro donne tratte da disegni e dipinti originali di Egon Schiele
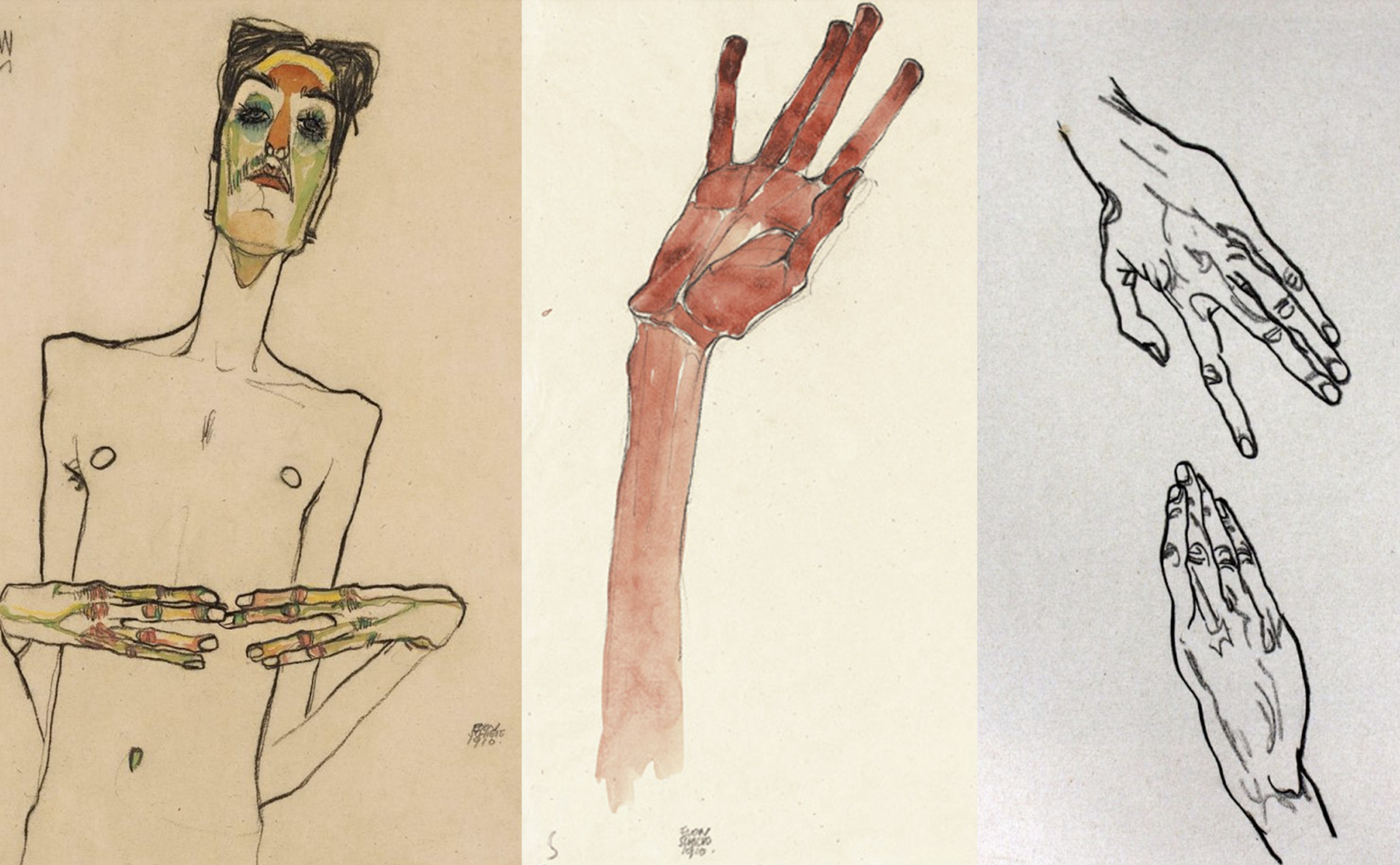
Mani tratte da disegni e dipinti originali di Egon Schiele
Quello che succede nella mente degli utenti è invece una forma di autoconvincimento, come quelle che si verificano quando leggiamo l’oroscopo o i consigli di una eightball, dove qualsiasi cosa che ci venga raccontata riguarda senza dubbio noi,è proprio quello che ci succederà. Di colpo il testo è stato scritto chiaramente su misura per noi.
Allo stesso modo davanti a una risposta di una AI text to image la nostra mente completa il gap fra le intenzioni e il risultato ponendoci a metà strada come latori di grandi significati dal grande controllo formale e dalla grande consapevolezza.
Un commento di un “AI artist”:
“man mano che verranno assimilate nella nostra quotidianità la gente capirà che ottenere bella roba non è affatto semplice, le perplessità su chi sia autore si risolveranno, la stessa cosa che successe quando con la grafica 3d tutti la sminuivano dicendo “fa tutto il computer””
Che però è esattamente quello che accade sul piano visivo con le AI text to image, visto che l’immagine la fa il computer — non operando non una miriade di calcoli per ottenere una immagine prevedibile come ad esempio accade con il 3D o con qualsiasi sistema parametrico di computer grafica in cui a un parametro corrisponde un risultato programmato, ma una miriade di scelte arbitrarie. O meglio, ci propone casualmente una miriade di scelte di qualcun altro, una montagna di semilavorati linguistici visivi di cui non sappiamo nulla, ma che hanno una loro coerenza interna.
Sul fatto che non sia affatto semplice, sarebbe come dire che è arte ottenere BAR BAR BAR sulle slot machine solo perchè è statisticamente difficile, tralasciando che il concetto di “roba buona” la dice tutta sul concetto di arte visiva che ha un utente di una AI text to image. Più che la creatività ricorda i processi mentali da cacciatore e raccoglitore che si attivano quando speriamo di trovare qualcosa di buono in un negozio di vestiti usati.
Proviamo a fare il contrario esatto e cerchiamo di “estrarre” dalla nostra mente un quadro arcinoto come la “Gioconda”.

Sei immagini generate con Stable Diffusion utilizzando sempre lo stesso prompt: “medium shot portrait of an enigmatic young woman with brown hair wearing a transparent veil on her head and a long sleeve green and light brown dress sitting on a wooden chair, looking in camera, arms resting on the chair, on a terrace, background shows hills a river and a arched bridge fading in the foggy distance, painted in leonardo da vinci style”
Non c’è “ricetta” che tenga, non riuscirete mai a ottenerla.
Quello che otterrete è invece una serie di immagini casuali superficialmente impapocchiate con un’aderenza puramente superficiale allo stile di Leonardo. Anche se fosse in grado di riprodurre alla perfezione lo stile di Leonardo, sarebbe comunque un’immagine diversa.
Vale tanto con la “Gioconda” quanto con il “Quadrato bianco su fondo bianco” di Kazimir Malevič.
Trovo comunque interessantissimo analizzare il modello di interazione che è stato scelto per Midjourney. L’utente produce un testo, il prompt che viene inviato alla AI, come fosse un brief inviato via chat a un collaboratore dall’altra parte del mondo. L’AI si prende il suo tempo e non ci risponde con una immagine soltanto, ce ne gira quattro. Tutte anche molto diverse fra di loro, tutte compatibili con il brief. Da qui in poi si procede scegliendo una delle proposte per averne la versione upscaled, ovvero a risoluzione di stampa, oppure si può scegliere una delle quattro immagini per avere un altro round creativo che tenga l’immagine selezionata come reference diretta. A quel punto la AI ci presenta le sue nuove quattro proposte cercando di distaccarsi il meno possibile dalla versione scelta.
E’ interessante perchè è esattamente quello che faccio per mestiere. Se parliamo di copertine di libri, ad esempio, ricevo un brief scritto. Sebbene possa capitare, non sempre il brief è accompagnato da una riunione a voce. Di solito si tratta di una email in cui mi viene illustrato l’obiettivo con alcune eventuali note creative sull’impostazione generale. A quel punto rispondo con la mia prima serie di proposte, 3 in genere ma possono essere anche molte di più se il progetto lo impone (per la collana Asimov - Storie della Fantascienza, edito da Oscar Vault Mondadori ne ho prodotte 25 trattandosi di 5 volumi).

Una parte delle proposte di copertina che ho realizzato per Asimov - Storie della Fantascienza, edito da Oscar Vault Mondadori
Fra le proposte ne viene scelta una e una soltanto su cui si procede o alla finalizzazione o a un possibile approfondimento se il progetto lo richiede. Questo metodo per me è un sistema infallibile per vendere una immagine originale nel minor tempo possibile e con il maggior grado di soddisfazione possibile per il mio cliente e non mi stupisce che la AI operi allo stesso modo: d'altronde anche lei deve cercare di vendere più immagini possibili nel minor tempo possibile con il grado di soddisfazione dei suoi clienti più alto possibile.
Questo perchè poter scegliere fra una serie di proposte estremamente diverse aiuta sicuramente a sceglierne una e non permette l’insorgere di crisi decisionali o di micro aggiustamenti. Le immagini sono molto diverse fra loro e cercare un compromesso sarebbe una perdita di tempo e denaro. Anche in questo caso, quindi, c’è una selezione fra molte immagini diverse, eppure l’autore di quelle immagini, quelle definitive resto io, non il cliente che ha scelto.
Un altro sintomo inequivocabile dello stesso problema è il bisogno di dare titoli estremamente calzanti con le immagini generate, come fossero degli estratti da un testo illustrato, dimostrando ulteriormente di non comprendere che l’unica forma veramente creativa è appunto quella di scrivere un testo traendo ispirazione dal lavoro di qualcun altro, ovvero la AI. A posteriori.
AI che ovviamente non viene quasi mai citata come autrice, ma sempre come strumento.
Dal suo profilo Facebook, Lev Manovic, docente di Computer Science Program al City University di New York, Graduate Center, U.S e esperto di nuovi media, scrive:
Text relations in AI Image Synthesis (after Roland Barthes)
For decades, we assumed that describing an image by words is limiting. This was one an important assumption of the arts in the modern era. For example, one of the key goals of visual modernism was to get rid of the “story,” having instead paintings explore their own visual languages. And this is also why “untitled” become a very common title for modern artworks. Refusing semantic labels that may limit what a viewer would see in an image.
This idea was not limited to the arts. For example, Roland Barthes suggested that newspaper text captions fixes the meaning of a newspaper photograph, limiting its potential ambiguity (e.g. a caption for newspaper image.) However, when I use AI tools such as #midjourney, my experience is very different. MJ "amplifies" your short phrase (e.g., a prompt), generating nuances, details, atmospheres, meanings, associations, and moods you did not specify - and often would never even imagine.
We can also find other relevant points in Barthes. For example, in Rhetoric of the Image (1964 ): “The linguistic message is indeed present in every image: as title, caption, accompanying press article, film dialogue, comic strip balloon.”
Within AI Image Synthesis paradigm, every image now literally has its linguistic code, its program - the text prompt that generated this image.
Going back to the idea the idea of fixing image’s meaning - Barthes's idea was later adopted by Media Studies which now uses the standard term “anchorage” (https://media-studies.com/anchorage).
“In the same way a word can have more than one definition, it is possible for signs to have different meanings, so producers will try to direct the audience’s interpretation towards a preferred reading of a media text by using anchorage. In newspapers and magazines, photographs are often accompanied by captions which are used to fix their meaning. This is probably the most common form of anchorage in the media. The choice of music can also influence our reaction to an advertisement or sequence in a film.”
AI Image Generation turns this on its head. The same text prompt can be used to generated many different versions of the same image. Every time you “run the code,” so to speak,” a new visual world emerges.
Un altro modo, estremamente interessante, di dire la stessa cosa: siamo e restiamo autori delle parole, ma i significanti che l’AI genera attraverso il medium visivo sono qualcosa che l’utente “would never even imagine” Il prompt viene quindi specificamente distinto da una forma di programmazione diretta dell’immagine, trattandosi di un layer altissimo basato su linguaggio naturale con quel “run the code” fra virgolette, “so to speak”. Quello che trovo contraddittorio di questa analisi però è la sua conclusione: “The same text prompt can be used to generated many different versions of the same image”, ovvero ”lo stesso prompt testuale può essere usato per generare molte versioni differenti della stessa immagine”. Trovo che sarebbe molto più corretto dire “Lo stesso prompt testuale può essere usato per generare molte immagini diverse che mantengono vera la stessa descrizione verbale” visto che l’equazione “same image” / “same prompt” è concettualmente problematica.
Parlare di molte versioni della stessa immagine è una contraddizione in termini, trattandosi di proposte che offrono soluzioni formali visive completamente diverse una dall’altra, immagini diverse, by design. Ha senza dubbio più senso parlare di diverse proposte creative visuali.
Una buona norma che propongo e che mi pare inquestionabile è che una volta che l’immagine è stata prodotta dalla AI, anche qualora venga manipolata come semilavorato per produrre una “nuova” immagine, specialmente nel caso in cui in questa nuova immagine l’originale della AI sia ancora chiaramente riconoscibile, la fonte vada citata, esattamente come faremmo con gli artisti in carne ed ossa.
Propongo anche che il prompt sia pubblico visto che, di fatto, è tutto quello di cui si compone l’operato dell’utente: il concetto scritto prima, la selezione dell’immagine poi, creando questa figura ibrida di committente e curatore di AI.
In questo senso fa riflettere il fatto che Midjourney offra solo nel suo piano a pagamento la feature di tenere nascosti i prompt dell’utente, per 20 dollari in più al mese. Questo apre alla possibilità di mentire sull’origine dell’immagine e permette a Midjourney di sgravarsi dell’annoso problema del Copyright visto che nessuno che non sia Midjourney stessa può dire da dove venga un'immagine creata con il loro servizio.
Tornando alla questione della concept art, quindi: le AI non possono filosoficamente essere usate come strumento per creare concept art, possono essere assoldate per svolgere il lavoro autoriale o parte di esso, come fossero artisti in carne ed ossa e vanno trattate come tali.
Provo a pormi un po’ di domande a voce alta, simulando degli scenari di utilizzo della AI in quanto autore a cui commissiono immagini, non in quanto strumento.
“Chiederesti mai a un artista di produrre un’immagine nello stile di un’altro artista, specie se vivo, contemporaneo?”
No. Perché puoi chiamare direttamente l’artista in questione e ingaggiarlo, invece di plagiarlo. Qualora sia impegnato o fuori budget puoi trovare un’altra soluzione, pensando ad un artista libero e alla portata della produzione. Qualora fosse morto, a meno che non si tratti di una boutade o di una attività a scopo didattico eviterei in assoluto: una strada “neoclassica” senza la comprensione profonda del linguaggio tecnico è solo kitsch.
“Occulteresti mai il nome di un artista del quale stai usando il lavoro?”
No, perchè oltre a esporti a dei rischi enormi dal punto di vista del diritto di autore, è banalmente ingiusto.
“Useresti mai un’immagine di un’altro artista correggendo qualche dettaglio che non ti soddisfa per poi pubblicarla come opera tua?”
No, perchè oltre ad essere un caso di furto di immagine, modificare un’immagine senza autorizzazione dell’autore e pubblicarla come propria non è una pratica consentita all’interno del diritto d’autore.
“Ruberesti mai un pezzo dell’opera di un artista senza menzionarlo come autore di quella parte dell’immagine?”
No, per gli stessi motivi.
“Proporresti mai a un editore un lavoro di un altro artista spacciandolo come integralmente tuo?”
Neanche, stessi motivi. Oltre al fatto che non ci dormirei la notte, ma quello è personale.
“Avendo a disposizione un falsario eccezionale, sfrutteresti mai l’immaginario di un altro artista per produrre articoli a fini di lucro senza chiedere l’autorizzazione all’autore in questione?”
No, perchè oltre a incappare in una probabile denuncia per plagio, lucrerei sulla proprietà intellettuale di qualcun altro quando invece potrei proporre una collaborazione direttamente all’artista in questione.
“Approfitteresti mai del lavoro a prezzi drogati che specifiche condizioni socioeconomiche creano (caporalato o sperequazione internazionale, per dire) per spendere meno a danno degli artisti che operano nella norma?”
Questo ovviamente è una questione di pura etica professionale. Molte aziende internazionali di grandissimo successo hanno nei fatti già risposto di SI, ma è chiaro a tutti che sarebbe più ragionevole rispondere NO.
E soprattutto:
“faresti mai una di queste cose elencate qua sopra solo per il fatto che l’autore in questione è completamente sconosciuto e nessuno mai verrà a sapere che esiste e che tu ci hai lavorato approfittando dell’impunità che questo comporta?”
No, mi farebbe orrore.
Sul fatto che possano avere un costo molto basso e che siano estremamente competitive e potenti non posso non aggiungere che anche entità come Fiverr — che promettono creatività su commissione a partire da 5 dollari a progetto — lo sono, e che chiunque li usi per progetti commerciali dovrebbe semplicemente vergognarsi. Ogni impresa o artista che potrebbe investire su un artista umano (con budget o offrendogli parte del guadagno) e invece taglia il costo in favore di una AI, o che mette in competizione economica uomo e intelligenza artificiale, va boicottata senza se e senza ma. Imprenditori del genere devono essere messi davanti alle loro responsabilità etiche: se non puoi permetterti un illustratore non usarlo del tutto, piuttosto che sostituirlo con una macchina. Sarebbe piuttosto auspicabile un impianto legislativo che promuova il “made by human” con sgravi fiscali per chi decida di investire nel lavoro di artisti umani, che certo aprirebbe a problemi specifici. Occorrerebbe verificare le dichiarazioni in merito per evitare hack illegali non indifferenti, come approfittare della sempre maggiore precisione delle AI per usarle comunque attraverso dei prestanome che permettano poi di richiedere anche gli sgravi fiscali del caso. Operare con le AI in ambito artistico con il solo scopo di saltare il bisogno di collaborare con un artista visivo è davvero irricevibile eticamente, specie considerato che si interviene finanziando delle aziende transnazionali che possono arricchirsi raccogliendo milioni di microtransazioni per i loro servizi lasciando completamente a secco lo scenario commerciale per gli artisti, proprio quella figure grazie alla quale la AI sono in grado di offrire le loro soluzioni.
L’AI opera infatti all’interno di un sistema di referencing complesso che parte da opere e immagini preesistenti, che operano come “cultura” per l’intelligenza artificiale. Per quanto atomizzate nel processo di sintesi per diffusione, le Ai sono allenate su dei dataset, dei database di materiale visivo, e possono essere istruite sottoponendo ulteriori informazioni da parte degli utenti, siano esse ulteriori richieste di perfezionamento o immagini da usare come reference. In questo processo (training e perfezionamento) il materiale copyrighted o comunque flaggato come non utilizzabile a questi scopi non dovrebbe finirci in alcun modo; ma non è così che va, è pieno di immagini che hanno sorgenti coperte da copyright e centinaia di artisti vengono saccheggiati dalle AI senza alcun consenso degli autori o degli aventi diritto. Qui potete trovare una lista pubblica di artisti che vengono riconosciuti da Midjourney e che fanno parte già del suo pool di training:
https://docs.google.com/spreadsheets/u/0/d/10i9Ip8tVSERAuMWbc6-H6BUFCoUGOQ91YzDvX--c4bk/htmlview?fbclid=IwAR0ozGOxn_QBb_8QAX0rHJxXYUPO0XQAYgxMezF9SWsUmtsc58znpbVPVKg#
Tralasciando gli autori non più in attività, non perchè sia meno grave, ma perchè mi pare semplicemente più eclatante il dolo, questi sono i risultati di prompt che includono solo il nome dell’autore di artisti vivi e vegeti e credo che siano decisamente problematici (di Bilal spunta pure il nome, come di molti altri la firma):

Abbastanza emblematico il fatto che esista un comando di prompt consigliato come “trending on artstation” ovvero “vai su artstation e ispirati lì dagli artisti che tirano ora, quali che siano non mi importa, basta che siano di successo su quel social network”.

L’ultima cena scimmiottando lo stile inconfondibile di HR Giger le cui opere sono sicuramente tutte coperte da copyright.

Un'immagine generata con Midjourney in cui si può vedere chiaramente un watermark imitato da un’immagine di un sito commerciale.

Un immagine creata con il nome di John Berkey nel prompt, le cui immagini sono attualmente coperte da copyright, in cui perfino la firma dell’artista viene imitata da Midjourney.
L'AI, esattamente come un essere umano, deve poter essere istruita per concepire dei limiti nella sua libertà di azione: se il corpus di Moebius non è stato aggiunto volontariamente dagli aventi diritto al database di training, l’AI non deve poterlo imitare, un po’ come succede con il riconoscimento automatico delle tracce audio o video su Youtube o Twitch attraverso la pattern recognition. L’utente potrà certamente inventarsi un prompt che usi termini generici per arrivarci vicino (lineart, flat, pastel colours, minimal, rocks, desert, white flying creature, mexico, sci fi), ma per arrivare alla configurazione stilistica esatta del grande autore francese non basteranno mille parole, riprova che i dataset devono essere composti da immagini aggiunte volontariamente dagli autori al pool di training — magari con il pagamento di cifre congrue o applicando principi di stakeholding aziendali.
Inutile dire che qualora si riconoscesse alle opere un “training right” si creerebbe anche una opportunità per una categoria infame di disegnatori che imiteranno artisti famosi solo per farsi medium di apprendimento per le AI, ma resterebbe comunque un’impresa più complessa che fare scraping di dati indiscriminato dalla rete appellandosi al “fair use”.

Queste sei immagini sono sei risultati del prompt “short hair brunette art nouveau front medium shot looking with golden vegetation and flowers decorations painting in pre raphaelite art deco style trending on artstation”. Le immagini sono completamente diverse con scelte e soluzioni formali completamente diverse, ma il prompt è sempre lo stesso e include riferimenti chiari a correnti artistiche create da artisti umani. Il fatto che le immagini siano coerenti fra di loro non dipende dalla mia bravura come “prompt artist”, visto che sono letteralmente ai miei primi tre prompt, ma dal fatto che le AI si appoggiano sul lavoro di esseri umani, che hanno raccolto sotto il nome di Art Nouveau, Art Déco, arte preraffaellita una serie di codici formali piuttosto precisi.

Queste sei sono sempre realizzate con lo stesso prompt, ma a cui ho rimosso il riferimento a uno stile preciso: “short hair beautiful young brunette medium shot front looking with golden vegetation and flowers decorations oil painting trending on artstation”.
Ho aggiunto “beautiful” e “young” solo perché sono caratteristiche che la AI ha automaticamente utilizzato nei risultati precedenti, siccome nell’Art Déco, nell’Art Nouveau e in quella dei preraffaelliti le donne sono praticamente sempre belle e giovani.
L’esperimento credo parli da solo e dimostra chiaramente da un lato l’importanza della presenza del lavoro di esseri umani nei dataset, umani che hanno svolto parte della semiosi visiva creando un abaco di segni e forme, dall’altro il fatto che non esiste alcun apporto autoriale nei prompt, visto che i risultati sono completamente diversi e casuali ogni volta e si tratta di poco più che gambling visuale/formale. Se non ci si appoggia al lavoro di qualcun’altro o di una corrente che crei un sistema di riferimento i risultati sono formalmente patetici.
Uno dei punti considerati emblematici dell’autentica autorialità di arte visiva dei “prompter” è la coerenza formale che alcune opere di alcuni specifici artisti raggiungono. Come a dire: se l’impronta dell’autore è riconoscibile nelle immagini, vuol dire che c’è per forza una qualche autorialità diretta. Posto che non è affatto una condizione necessaria, ne sia l’esempio questa serie di copertine di Spiderman.

Queste tre copertine sono state commissionate dalla stessa testata, sono di tre autori completamente diversi eppure hanno una serie di fattori ricorrenti fortissimi: il soggetto, la sua centralità, il nome della testata, la città. In sostanza: il fatto che il brief sia talmente forte da farsi strada nell’opera non toglie che sempre di un brief si tratta. I tre disegni sono dei tre autori diversi, non dell’editor Marvel che ha scritto il brief.
Ora,: e ci tengo a dire che per forza di cose dovrò entrare estremamente nello specifico tecnico per spiegarmi, analizziamo alcune immagini.

Immagini generate da una AI postate da Francesco D’Isa sul suo profilo Facebook.
Queste sono immagini dello stesso utente Midjourney, Francesco D’Isa, fatte a brevissimo giro l’una dall’altra. I soggetti sono simili: giovani ragazze con i capelli rossi, pelle chiara, integrazioni di tentacoli e strani elementi organici, background minimali, rendering pittorico figurativo. Visivamente, però sono opere diversissime nelle scelte formali di resa dei volumi, dei materiali. Quella al centro ha un rendering con i neri altissimi e saturissimi, il nero è completamente omesso e ha uno stile più graficizzato di pittura, ombre nettissime con una palette drasticamente limitata, un segno ben visibile e una sintesi dei volumi “apollinea” che imita la realtà, tuttavia non realistica e che permette l’integrazione dei tentacoli in un sistema di passaggio osmotico fra la figura reale della ragazza e quella surrelare dei tentacoli. L’immagine a destra invece è il lavoro di un pittore che opera sul vero, con una tecnica completamente diversa, con una palette con un range dinamico esteso non stilizzata, che usa i colori fino a spingersi dalle parti del nero, che tiene conto delle migliaia di sfumature che un incarnato realistico impone con tanto di subsurface scattering, luci con diverse temperatore colore, riverberi colorati con ombre portate decise senza mai diventare grafiche, in cui il segno pittorico viene fatto sparire in favore di un’immagine fotografica organica. L’anatomia è infinitamente più realistica, non sta dipingendo esclusivamente dalla mente, è pittura che viene dall’osservazione, a differenza della precedente. Dalle orecchie al naso possiamo senza dubbio dire che si tratti di un artista diverso. Questa immagine ci fa sentire tutti i muscoli del volto del soggetto, permettendoci di comprendere la sua espressione per portarci in una dimensione di empatia totale anche grazie agli occhi aperti e al loro accento cromatico. Anche gli interventi dei tentacoli sono diversi, sembrano più dei cutout realizzati con una tecnica pittorica a parte e applicati in seguito, come in un découpage digitale, visto che sembrano non essere perfettamente coerenti con il sistema di illuminazione e lo stile della figura principale — una scelta forte da un punto di vista visivo, dato il realismo del resto. La prima immagine fa testo a sé, probabilmente figlia di un prompt sensibilmente diverso, ha un tipo di sintesi pittorica e anatomica antica, viene da un altro pianeta, da altri linguaggi, è culturalmente lontanissima dalle altre due. Il modo di trattare i capelli e gli inserti entomologici, animali e vegetali, è assolutamente lontano dal principio di integrazione che governa le altre due immagini, hanno un significato squisitamente simbolico, esaltato dall’orizzonte astratto nello sfondo. Anche qui c’è una concezione visiva della rappresentazione del corpo, dei materiali, della luce e dello spazio in generale completamente diversa.
Per me la continuità di soggetto e temi, esattamente come per le copertine di Spiderman, non può essere considerata un fattore che determina l’autorialità visiva. Così come non lo farei con immagini di pittori diversi che partecipino ad una mostra con lo stesso tema da rappresentare, che è esattamente quello che queste tre immagini proposte da Midjourney sembrano essere.
Mi rendo conto che potrebbe sembrare un discorso limitato dalla visione che ho della creatività che si è formata su altri medium, ma se andiamo a vedere nel dettaglio posso dimostrare che non è così.
Anche accettando che bisognerebbe guardare al lavoro di un prompter su AI per quello che è e non per quello che potrebbe essere, ovvero un’immagine generata con un AI che ragiona in termini di metalinguaggi e non un vero dipinto, pur mettendo da parte l’ovvietà che questa distinzione sarà possibile farla solo davanti alla buona fede di un artista che dichiari la provenienza dell’immagine. Questo tenendo conto che fra meno di un anno avremo immagini prodotte da AI TTI che saranno indistinguibili da immagini create da esseri umani.
Pur considerando tutto questo, quello che vedo in un autore che si attribuisca la creazione delle tre opere sopra, è una superficialità in cui le scelte e le caratteristiche formali dell’immagine sembrano contare sempre meno quanto più non costituiscono il frutto del lavoro diretto dell’artista sul medium. Sembrano più ridotti a riempitivi decorativi bene accetti fra grossi blocchi concettuali, che rimandano cioè a delle idee generali. In questo caso: donna efebica e delicata integrata con creature universalmente considerate brutte, inquietanti o schifose, insetti o tentacoli, nel tentativo di creare un’immagine che generi da un lato contrasto, dall’altro la rottura di uno stereotipo e quindi integrazione. Ma il modo di affrontare l’immagine in termini formali è completamente fuori dal controllo diretto del prompter, come se ad ascoltare Marsilio Ficino non ci fosse stato solo Botticelli, ma anche Paolo Pollaiolo, creando due versioni completamente diverse dello stesso concetto a parole, due opere che denotano soluzioni formali significativamente diverse, poetiche diverse, artisti diversi, e noi attribuissimo tutte e due le due immagini al Ficino.
Da amante della pittura e del disegno tradizionali come di quelli digitali, so perfettamente che con il digitale la scelta si traduce in un processo esatto. È possibile controllare la materia di un‘immagine fino al pixel, all’atomo, con la possibilità di correggere quante volte si vuole. L’errore in una immagine digitale è qualcosa che correggi, se capita. Invece, la ricchezza di dettagli che l’imprevedibilità della materia regala è un fattore fondamentale e unico della bellezza dell’arte realizzata con tecnica tradizionale.
Disegnare con l’acquerello è simile all’andare a cavallo (non vorrei dire una bestialità ma sono convinto di averlo sentito dire a Gipi): sai dove vuoi andare, ma il cavallo ti ci porterà per conto suo, facendo una strada che non è esattamente quella che avresti fatto tu a piedi. Puoi forzarlo tirando le redini, se vedi che non vuole saperne, ma non puoi controllare ogni suo movimento. Disegnare con materiali ad alto livello di imprevedibilità come la carta, i pennelli, l’acqua e i pigmenti impone un processo continuo di aggiustamento della nostra intenzione, in uno scambio continuo fra visione e percezione in cui l’artista deve trovare attimo dopo attimo dove sia il bello in quello che sta succedendo sul suo supporto di disegno, accogliere o imporsi, scoprire bellezza o individuare errori. E anche davanti agli errori l’approccio è diverso: in tradizionale, spesso con gli errori finisci per conviverci, per non buttare il resto dell’opera. Dipingere può diventare quindi, a vari gradi di imprevedibilità e in diverse fasi del lavoro, una sorta di quesito continuo. Un confronto costante fra l’idea di partenza, l’immagine mentale e la valutazione su un piano visivo delle opportunità di significazione che gli si pongono davanti. Per alcuni artisti è uno stato di trance in cui si è solo nella fase attiva, di output, ma per alcuni c’è uno scambio che somiglia a un match di tennis fra proposta creativa e risposta critica, di input. Come un attore che salga e scenda di continuo da un palco per rivedere il suo ultimo gesto. È così che avviene anche anche nelle GAN, “Genarative Adversarial Network”, le AI che creano le immagini nelle AI TTI. Si chiamano “adversarial” proprio perchè il risultato è il frutto di un conflitto fra due AI: quella che crea e quella che giudica.
Qualunque sia il modo di affrontare l’immagine si tratta comunque di scelte formali, consapevoli o inconsapevoli che siano, di interpretare, di essere travolti, di arricchire la visione, scegliere continuamente e creare con il nostro corpo, il corpo dell’autore.
La scelta di un utenti di AI TTI si limita a due fasi: quella di produrre un brief, magari molto preciso perché il committente conosce il suo collaboratore da anni. Ci può essere una fase di revisione con note anche molto dettagliate. Note che anche fossero visive servono comunque per richiedere ulteriori immagini o modifiche a una entità terza su cui non si ha alcun controllo e che opera le scelte visive di rappresentazione del nostro brief al posto nostro, che plasma le informazioni digitali al posto nostro.
E poi la seconda, quella della scelta dell’elaborato finale.

Un esempio di note visive e scritte per correggere una foto con metodo tradizionale.
Capitolo 7
Solo uno strumento
Posto che abbiamo capito serenamente che le AI sono a tutti gli effetti degli autori di arte visiva e noi poco più che clienti, committenti, spettatori e in qualche nobile caso editor, dobbiamo cominciare a sgranchire la mente su un altro aspetto, che è quello commerciale.
Questi artisti artificiali operano attraverso uno sportello, spesso dietro un paywall, che fa capo a strutture informatiche privatissime, costosissime, complessissime e pure inquinantissime di cui l’utente non sa nulla.
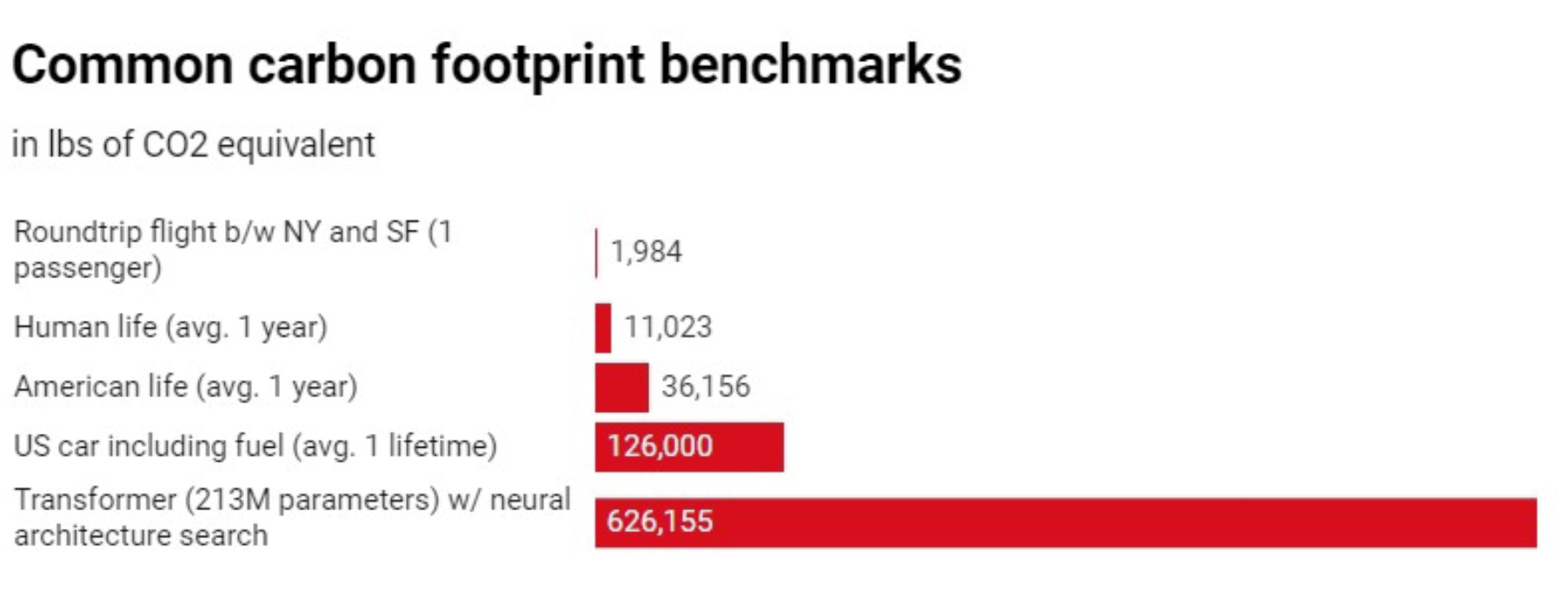
University of Massachusetts, Amherst, LCA del training di modelli di AI.
Oltre a consumare un delirio di energia per ogni fase di training, anche ogni giro di slot machine per generare una immagine su queste AI produce CO2 attivando server con centinaia di GPU.
Alcuni altri commenti sull’argomento:
“Midjourney è solo un nuovo tipo di software per disegnare. Tutta questa paura è completamente irrazionale.”
“E’ come con l’arrivo della fotografia. Spazzò via gli artistucoli minori. Ma creò da un lato i grandi fotografi e diede vita alla rinascita della pittura. E’ solo un nuovo strumento e ci sarà lavoro per chi usa il disegno, chi usa la fotografia e chi usa Midjourney.“
“Questa immagine non l’ho disegnata io! l’ha fatta un robot! Paura eh! Ho solo dovuto scrivere delle parole per avere la mia immagine come la vedete. Ma non è altro che uno strumento. Tutto qua: abbracciate il futuro senza pregiudizi. ”
In quest’ultimo passaggio è particolarmente interessante che nello stesso testo si dica:”Questa immagine non l’ho disegnata io! l’ha fatta un robot!” e “Ma non è altro che uno strumento.”
Una opinione diffusa sulle AI text to image è che siano solo un nuovo strumento a nostra disposizione, paragonando spesso il loro avvento all’arrivo della fotografia.
Posto che la fotografia, come sappiamo, ha comunque tolto molto lavoro ai pittori e agli illustratori, specie nell’editoria, visto che un tempo per avere un’immagine su un libro o su un manifesto non c’era altro modo che chiederla a un artista grafico e la fotografia di colpo abbatteva i costi e i tempi per avere immagini estremamente realistiche, quello che però non sembra essere molto chiaro a chi paragona l’arrivo della fotografia all’arrivo della AI text to image, è che la fotografia, dopo un lungo periodo di assestamento, si è definita come altro medium, rispetto al disegno e alla pittura.
Un dipinto, per quanto iperrealista possa essere, resta pittura, una foto, per grafica che possa essere resta una foto. Sono medium diversi distinti da una mole considerevole di fattori strutturali, e sono rimasti distinti anche con l’arrivo del digitale nella fotografia, per quanto esistano tantissimi artisti che operano in ambiti transizionali.
La AI text to image, invece, è un’entità che opera sullo stesso identico medium di un artista visivo digitale (che sia un disegnatore, pittore o fotografo), ha lo stesso tipo di output e arriverà a breve a essere tecnicamente indistinguibile dal lavoro di un essere umano, qualsiasi sia lo strumento che si scelga di usare, pennelli, macchine fotografiche, matite, penne a sfera o rendering 3d.
Neanche l’arte tradizionale resta dominio esclusivo degli umani visto che sono molteplici gli interventi di AI su supporti fisici con strumenti di belle arti, spesso anche partendo dalla rappresentazione del vero.
Chiunque dica che si tratta solo di un nuovo strumento non ha idea di cosa parla o ha paura di guardare in faccia la realtà: le AI text to image sono entità in grado di operare autonomamente processi di semiosi visiva avanzata e lo possono fare con o senza un input umano. Già da adesso l’input umano è solo un modo per monetizzare il processo, niente di più. È uno strumento di guadagno per le aziende che erogano il servizio, non il contrario. A breve non servirà più neanche quello perchè il modello di business si evolverà.
Sempre dai social, un altro utente di servizi text to image:
“pensa che rottura di palle se un artista dovesse inventarsi gli strumenti con cui lavorare”
Rischiamo di rimpiangerla quella rottura che, a margine, è fra le gioie più grandi del fare arte e ha reso irraggiungibili tantissimi artisti, formalisti o concettuali che siano: la libertà di costruirsi il proprio sistema di formalizzazione della visione.
Un ulteriore problema è infatti l’endemica mancanza di libertà nell’affidarsi a un’entità che comunque ha una sua visione, dei bias concettuali, formali, filosofici e politici che le AI hanno e potranno avere in futuro considerando questi limiti e queste prese di posizione come un dato di fatto scontato. Se anche accettassi, e non la accetto, l’idea che si tratti effettivamente di uno strumento come gli altri, non potrei sopportare uno strumento che scelga al posto mio cosa va bene e cosa no nei contenuti delle mie opere.
Le AI andranno con ogni probabilità nella direzione di miniaturizzare, specializzare e parcellizzare il loro intervento, interlacciandosi alle attività dell’uomo, assistendo le sue azioni continuamente, cercando di integrarsi alle sue attività fino a cercare di sparire in un processo di mimesi prassitaria e controllo.
Questo, se possibile, è peggio ancora, uno strumento che aggiusti continuamente la forma della mia espressione per restituirmi qualcosa che mi piaccia, che mi soddisfi. Pensiamo all’attuale strumento di stabilizzazione del tratto presente nei principali software di disegno a interfaccia naturale, di quelli che permettono di disegnare con una penna su uno schermo. Già così è sicuramente fra le principali cause dell’omologazione grafica degli autori di disegno digitale, operando una media matematica fra milioni di gestualità diverse, schiacciandole letteralmente su una media matematica gaussiana. Immaginiamo invece un tool integrato che sostituisca in tempo reale i nostri tratti con i tratti dei grandi disegnatori: dal tratto spigoloso di Chester Gould, a quello abbacinante di Moebius, alle masse pittoriche gommose di James Jean. Sarebbe come un pianoforte che cerchi sempre di correggere la mia musica per farmi sentire una melodia che sicuramente mi piacerà, o che cerchi di suonare nello stile di qualcun altro. Una modalità di disegno “a stile assistito”, lo svuotamento del gesto grafico, la cancellazione del processo di scelta e valutazione, di sperimentare in ambiti non tracciati o profilati, l’azzeramento espressivo. Ancora una volta: la contraffazione della significazione e della creatività scambiati per una forma di appagamento immediato.
Se anche volessimo prenderlo in considerazione come strumento, credo possa essere tranquillamente considerato il peggiore degli strumenti possibili, un impedimento costante a misurarsi direttamente con le immagini o con chi le fa.
Una nota ulteriore sul ruolo di strumento delle AI.Un altro modo di vedere una realtà come Midjourney è quella di considerarla una incredibile, gigantesca opera d’arte generativa collaborativa. Un sistema che produce diversi risultati secondo un sistema di regole creato dall’autore, con pesi ideologico formali hard coded nel motore di funzionamento della AI, in cui ogni immagine generata con l'intervento umano è parte di un magnum opus del creatore di Midjourney.Se anche così fosse il concetto non cambia: l’utente non è certamente l’autore, può considerarsi parte del meccanismo di questa mirabolante opera.
Capitolo 8
You Are (Not) Fair Enough
Detto questo, concentrandosi proprio concetto di “fair use”.
Posto che gli stati uniti non hanno un vero e proprio codice civile e che quello che fa giurisprudenza sono le sentenze dei processi, restando per un istante alle immagini generate della AI, i dataset forniscono alla AI la grammatica visiva per la definizione di stili grafici, di principi compositivi, per la definizione della forma, in breve. Considerato il fatto che è la perizia formale a rendere interessante una text to image AI, la sua conoscenza di stili e opere è letteralmente la sua key feature.
Il “fair use” dei dati di internet per fare training di AI è stato definito tale in un momento storico in cui non si prospettava di certo l’ingresso in un campo industriale e commerciale di un nuovo attore che, a scopo di lucro, proponga servizi a pagamento in competizione diretta con i proprietari dei dati stessi. Gli autori delle varie AI si appellano quindi all’uso statistico/accademico di questi dati che gli è stato concesso in un contesto completamente diverso, in cui le figure coinvolte non sono neanche state interpellate.
L’autore di Midjourney, in una intervista a the verge, si ripara a mio avviso in maniera sofistica e faziosa con una risposta che non lascia dubbi su quale sia la sua posizione in materia:
“Speaking of training data, one contentious aspect here is the issue of ownership. Current US law says you can’t copyright AI-generated art, but we don’t quite know whether people can assert copyright over images used in training data. Artists and designers work hard to develop a particular style, but what happens if their work can now be copied by AI bots? Have you had many discussions about this?
We do have a lot of artists in the community, and I’d say they’re universally positive about the tool, and they think it’s gonna make them much more productive and improve their lives a lot. And we are constantly talking to them and asking, “Are you okay? Do you feel good about this?” We also do these office hours where I’ll sit on voice for four hours with like 1,000 people and just answer questions.
A lot of the famous artists who use the platform, they’re all saying the same thing, and it’s really interesting. They say, “I feel like Midjourney is an art student, and it has its own style, and when you invoke my name to create an image, it’s like asking an art student to make something inspired by my art. And generally, as an artist, I want people to be inspired by the things that I make.”
A fronte di un livello così basso del discorso (“parliamo con molti artisti della nostra community” e una chiosa che suona come “alla gente fa piacere essere copiata perchè si sente importante come i grandi maestri”) credo serva un intervento delle istituzioni che ridefiniscano chiaramente le norme del “fair use” e che introducano nel copyright una voce che riguardi il “training right”.
Inutile dire che qualora si riconoscesse alle opere un “training right” si creerebbe anche una opportunità per una categoria infame di disegnatori che imiteranno artisti famosi solo per farsi medium di apprendimento per le AI, ma resterebbe comunque un’impresa più complessa che fare scraping di dati indiscriminato dalla rete appellandosi al “fair use”.
Uno degli argomenti più pigri e stupidi che ho letto in giro come risposta a persone che intuivano una possibile problematica in questo processo di apprendimento da parte di una macchina è “studiano, apprendono e si si ispirano, esattamente come hanno sempre fatto gli artisti da quando esiste l’uomo”.
L’ho letto ovunque.
Posto che ovviamente reputo la cultura un bene inalienabile universale dell’umanità tutta, un bene che deve essere libero di essere studiato, contestato, stravolto in ogni modo possibile da ogni essere umano, credo ci sia una enorme differenza fra cultura e dataset, fra uomo e AI, fra strumento artistico, tecnica e servizio a pagamento per una prestazione, fra individuo libero e azienda privata a scopo di lucro.
Per contrasto, vi porto tre esempi sani di uso di questa tecnologia e che reputo davvero fair:
PHAEDO di Kioxia
https://brand.kioxia.com/en-jp/articles/article18.html
Phaedo è un manga disegnato (con carta e penna attraverso un braccio meccanico) interamente da una AI che è stata istruita su tutte le opere di Tezuka per celebrare il grande autore giapponese. Questa roba è cristallina, per me. Le fonti sono della società che fa capo al diretto interessato con l'approvazione della famiglia. I dataset sono stati informati con materiale di prima mano e solo con quelli che servono alla creazione dell’opera.
Opacità dell'operazione: zero.
AIMI
https://www.aimi.fm/
Un progetto musicale in cui a una serie di musicisti sono stati commissionati dei data set curati, musica originale creata per poi essere rielaborata da un sistema di AI in grado di creare infinite variazioni, remix, edit e quant’altro.
QUALUNQUE SISTEMA DI AI TEXT TO IMAGE CONFIGURATA INDIPENDENTEMENTE CON DATA SET DI PROPRIETA’ DELL’ARTISTA
Sistemi di AI text to image locali e indipendenti, ovvero python scripts che consentono di creare la propria intelligenza artificiale basata su una GAN partendo da scipt open source. Questo approccio consente una autentica sperimentazione e la possibilità di curarsi i propri dataset senza paura di abusare del lavoro di altri artisti e soprattutto con un controllo del risultato formale assolutamente non comparabile
Una critica che mi è stata mossa da un utente Midjourney durante una conversazione parlando della legittimità dei dataset:
“sul copyright sono davvero criticissimo: se togliamo la possibilità alle AI (e quindi a tutti, non vedo alcun motivo di fare un’eccezione) di usare immagini copyright free mi pare davvero un’ingiustizia. Duchamp non ha chiesto certo il permesso per mettere i baffi alla Gioconda. Non sarà certo peggio un paio di baffi rispetto a essere inserito nel data set di Midjourney.”
“e quindi a tutti, non vedo alcun motivo di fare un’eccezione”.
E chi lo dice che non ha senso e che le AI, specie quelle che fanno capo a aziende private che le noleggiano come servizio a scopo di lucro vadano considerate eticamente al pari di un essere umano?
Soprattutto, un essere umano libero, un vandalo provocatore come Duchamp, un’artista che ha fatto un percorso culturale talmente lungo e complesso che per mettere sottosopra il mercato dell’arte tutta ha capito che gli bastavano un pennello da due centesimi e due gesti in croce con cui fare i baffi a una copia della Gioconda presa da un rigattiere a due soldi e esporla con l’occasione giusta, paragonato con l’utente di un servizio internazionale on demand a pagamento di cui l’utente non sa niente, dal quale riceve immagini di cui non sa niente prodotte sotto un EULA di cui l’utente non sa niente, con mille scelte a monte e restrizioni di cui l’utente non sa niente, distribuito su una rete internet privata a pagamento di un tier 1 provider erogato su un dispositivo di consumer electronics di cui l’utente non sa nulla, che si collega a server di calcolo mastodontici ultra inquinanti di cui l’utente non sa niente su cui gira un software che usa indiscriminatamente il lavoro di centinaia di migliaia di autori morti o ignari di essere nei dataset di cui l’utente non sa nulla, per produrre un’immagine che nel migliore dei casi stupirà per essere quanto di più lontano da quello che ci si aspettava (magari in meglio) è oltre la barriera del ridicolo inconcepibile. La Gioconda, in Duchamp, ha infatti un valore che va ben al di la di un semplice elemento da kitbashing o reference, parliamo di una immagine simbolo, che Duchamp conosce alla perfezione e che viene usata in quanto tale e non per predarne le interiora.
E’ un’operazione di linguaggio, un discorso culturale su una scala completamente diversa in cui la Gioconda è indeformabile, un simbolo, non una library di strumentini precotti da rubacchiare senza neanche saperlo o peggio ancora accorgendosene e sperando che nessuno se ne accorga.
Per concludere con l’obiezione che ho citato sopra, un conto è intervenire su un’opera come tale, che sia in chiave esplicitamente citazionista, con un deturnamento o una variazione, ma sempre e comunque con un dialogo schietto, colto e consapevole fra opere e autori, un conto è divorare indiscriminatamente il lavoro di tutti gli artisti per farlo sparire in un sistema superinformato che non cita niente e nessuno, che non dialoga o risponde a niente e nessuno, che non mi da neanche la possibilità di chiedermi cosa sia la Gioconda.
Nessuno vieta agli artisti di prendere la Gioconda e fargli i baffi, credo solo che per farlo vada scelto il modo e lo strumento più bello, dissacratorio e liberatorio possibile, come ci ha insegnato Duchamp.
Un modo che preveda nella sua pipeline lo sfruttamento sistemico gratuito e senza alcuna approvazione del lavoro di un artista scomparso, a vantaggio di una azienda privata con stakeholder più che facoltosi finalizzata a sostituirsi al concetto stesso di autore di immagini è sicuramente un modo, permettetemi però di avere una enorme disistima per chiunque lo pratichi.
Per farla breve: sono il primo a dire che non dovrebbe mai esserci alcun dogma morale che proibisca a un artista di bruciare la vocazione di San Matteo di Caravaggio per fargli una foto mentre brucia, ciò non toglie che sarebbe probabilmente una azione stupida e banale prima di tutto sul piano artistico, poi perchè statisticamente produrrebbe un’opera di alcun valore che non sia quello dello scandalo etico alle spese di un’opera che è già sicuramente e universalmente riconosciuta come eccezionale, di un autore che ha sempre autenticamente innovato, sfidato ogni forma di morale fosse essa laica o cattolico cristiana.
Questo tralasciando che in un epoca come la nostra emulazioni e riflessioni chiaramente banali, nocive e sostanzialmente parassitarie si moltiplicherebbero in un istante creando una bolla di disperati che cercano di cavalcare un trend completamente autodistruttivo.
Un altro appunto e di pari rilevanza è anche che quando parliamo di copia o plagio in ambito digitale ci si immagina sempre il concetto di duplicare byte per byte, senza perdita di informazione, un contenuto già esistente per incollarlo da qualche altra parte o per usarlo come semilavorato per creare altre opere.
Nell’arte, però, esistono infinite sfumature fra la copia 1 a 1, il furto e un’opera originale e possono essere anche estremamente più gravi dell’intestarsi un’opera altrui. Esistono attività come falsificare e imitare che possono essere foriere di situazioni estremamente gravi. La falsificazione, in particolare, trovo sia particolarmente importante da analizzare. Un falsario che si rispetti è quello che riesce, senza essere scoperto, a produrre un dipinto e a inserirlo nella produzione di un pittore musealizzato e storicizzato, magari 400 anni dopo la sua morte. Il falsario crea da zero un’opera che non c’è mai stata nel corpus di quell’autore, ingannando grazie alla perizia tecnica e ai materiali usati tutta una schiera di periti tecnici e chimici, critici e storici dell’arte.
Falsificare è davvero molto più grave che copiare, perchè nella copia l’opera originale oggetto dell’operazione resta inadulterata e anzi, il valore dell’originale si esalta proprio per contrasto con la copia: una copia resta una copia, l’opera illegittima ha comunque un suo autore. Nel caso di un falsario che riesca a superare il test di una verifica il danno è fatto, è sostanzialmente irreversibile. Un falsario, per essere in grado di creare una nuova opera di un pittore antico è costretto a calarsi nella realtà dell’autore ricreando condizioni operative (penso alla nostro modo di percepire la luce, ai soggetti utili impossibili da trovare, ai materiali di lavoro dell’epoca che non tradiscano la loro natura moderna neanche ad ispezioni chimiche) difficilissime da gestire in un mondo che è radicalmente cambiato. Un lavoro immane e difficilissimo, con un fattore enorme di rischio legale.
Posto quindi che il training sulle opere di artisti umani dovrebbe essere fatto con l’esplicita volontà degli autori, posto che è vero che le AI TTI non copiano nel senso digitale del termine, possono scopiazzare nel senso umano del termine. Imitano nel senso dell’imitazione industriale illegittima e falsificano stili e opere di migliaia di autori. Se anche plagiassero, falsificassero, scopiazzassero con la stessa incidenza per disegno di un essere umano, sarebbe comunque un incremento esponenziale considerata la mole spropositata di immagini per secondo che queste entità sono in grado di produrre. Purtroppo non è neanche così, visto che tutte le AI TTI messe insieme producono più immagini in un giorno di tutta l'umanità in un anno e non possono fare altro che basarsi su data set fatti di lavori altrui, senza alcun concetto del plagio e del contesto che possa farlo dubitare della legittimità dei loro elaborati grafici. La naturale scarsa conoscenza della provenienza delle immagini presenti nei data set, parliamo pur sempre di 5,8 miliardi di immagini nel data set LAION usato da Stable Diffusion, fa il resto. La AI propone, l’utente fallisce il “knowledge check” e prende l’immagine per buona, originale.

Una “balena cubista” (sopra) creata da Dall-E con il prompt di un utente e il logo di Docker (sotto), un software open source per la virtualizzazione di piattaforme. L’autore della balena ovviamente non aveva nessuna idea del fatto che Dall-E avesse scopiazzato maldestramente un logo di fama internazionale.
Capitolo 9
Anima
"State tranquilli, l'arte delle macchine non sarà mai comparabile a quella dell'uomo, le macchine infatti non avranno mai un'anima."
Mi spiace segnalare che non è che sia proprio un ottimo argomento per stare tranquilli visto che, fino a prova contraria, dell'anima pare non ci sia traccia neanche nell'essere umano.
A parte gli scherzi, vorrei concentrarmi sulla versione un pelo più razionale della stessa obiezione, ovvero che nessuna AI potrà mai avere il senso del contesto e i sentimenti di un essere umano, che sarà quindi inevitabilmente su un gradino inferiore rispetto all’uomo quando si tratta di produrre immagini o ancora meglio storie che parlino all’interiorità delle persone: anche considerando il postulato iniziale come vero, non è necessario che un’AI abbia un reale senso del contesto e dei sentimenti per produrre arte che interessi o che emozioni, basta che ci siano le condizioni perchè ci persuadiamo che ne abbia.
Un primo fattore perchè accada è già alle porte ed è determinante. Sono gli utenti che, prodotte le immagini con un AI, proporranno il prodotto della generazione al pubblico o a un editore. Oggi se analizziamo la produzione di un autore maturo, eclettico o meno che sia, possiamo individuare con una certa precisione una serie di caratteristiche, originali o meno che siano, ricorrenti e distintive. Per differenza, se questo autore pubblicasse oggi una immagine realizzata con Midjourney o qualsiasi altra AI sul suo feed di immagini noteremmo una vistosa discontinuità con il suo approccio solito, si spezzerebbero tutti i fili del suo processo formale, sarebbe lapalissiano anche a un incompetente totale lo scarto tipologico di tutte le caratteristiche artistiche, su un piano immediato, intuitivo.
Questo scarto permette di distinguere con facilità, ci permette di dire con una certa sicurezza che quelle immagini hanno un'origine diversa dagli altri post del feed, non sono immagini create dall’artista in questione. Non sono sue. Per chi ne sa qualcosa poi, l'ipotesi che siano frutto di una AI sarebbe più che ragionevole e chiunque storcerebbe il naso di fronte ad una affermazione opaca dell'autore sulla tecnica utilizzata, un generico "tecnica digitale", per dire.
Cosa succede però di fronte a un artista di cui non abbiamo mai visto opera che non sia AI generated? Meglio ancora un novello autore di immagini o di storie a fumetti che di presentasse da noi editori con un portfolio di immagini che vediamo per la prima volta. Considerando che a breve avremo immagini prive dei glitch tipici di un AI, quindi indistinguibili dal lavoro di un essere umano, se un nuovo artista dovesse omettere l’origine delle immagini, ma anzi presentarle al pubblico come sue saremmo già nell’ordine di idee che quelle immagini siano frutto di sensibilità, sentimenti, comprensione del contesto e compagnia cantante.
Questo tralasciando che anche il prompt potrebbe non essere suo ma generato da un Ai partendo, chessò, dalla sua profilazione social.
Anche l’obiezione che possano essere lontane da temi del contemporaneo o autenticamente vicine alla nostra sensibilità è infatti solo wishful thinking.
Se sembra inverosimile un evoluzione così rapida verso immagini che parleranno del nostro mondo e non di quello di qualche pittore o illustratore fuori moda, è perché non stiamo considerando alcuni aspetti molto importanti.
In particolare, l'enorme differenza la faranno i dataset su cui le AI si informano.
Oggi le AI possono informarsi e allenarsi partendo da immagini, testi, interazioni e post sui social media o qualunque contenuto incontri i requisiti del “fair use” (e su questo concetto c’è moltissimo da dire, ma lo approfondiremo dopo). Nonostante si tratti di quella stessa enormità di dati che hanno permesso la costruzione di strutture informate in grado di cambiare il nostro modo di relazionarci, il nostro senso di comunità, la nostra politica, si parla pur sempre di frammenti sparsi della nostra vita e poco più, attimi che vengono campionati in varie forme (post, commenti, like, reaction, click, etc), ma che poi devono essere processati, analizzati e usati per stimolarci a fini di lucro, trattandosi pur sempre di dati bidimensionali che restituiscono una forma estremamente stilizzata del reale. A questo bisogna aggiungere che ogni post è frutto di una qualche forma di performance speciale: che sia una grande opera, un post su un blog o un commento sui social network, ci si espone quando si scrive o quando si posta una immagine o un video ed è quindi ovvio che si cerchi di farlo al meglio. E’ un piccolo evento fuori dai nostri standard privati, in discontinuità con la nostra vita “vera”. Con l’arrivo del Metaverso, invece, le cose cambieranno drasticamente e la tipologia di dati che una società (come ad esempio Meta) riceverà sara esponenzialmente più complessa di quella di normali social network. Nel metaverso i dati saranno continui nel tempo, ogni elemento del metaverso genererà dati utili su una quantità di assi impensabili prima: come ci muoviamo, come parliamo, con che tono di voce, su quali argomenti, con chi parliamo davvero, le nostre attività collettive, cosa facciamo quando siamo soli e chi ne ha più ne metta. Il tutto come stream continuo nello spazio e nel tempo.
Aggiungiamoci che con ogni probabilità, per trackare i nostri movimenti e permetterci di parlare nel metaverso, le device wearable avranno occhi e microfoni puntati verso il nostro mondo, quello vero, continuamente. Di sicuro avremo modo di disabilitare una simile invasione della privacy, ma a che prezzo? Vorrete davvero perdere la funzione che permetterà al nostro visore VR di mappare l’ultima posizione nota del mazzo di chiavi della nostra macchina per una banale paranoia da complotto dei tech giants?
Una simile, continua mole di dati così sofisticati renderebbero il training di una AI semplicemente fuori da ogni possibile immaginazione, in grado di approssimare statisticamente la comprensione dei nostri stati d’animo, il “sentiment”, lo “zeitgeist” della nostra specie in ogni momento, su qualsiasi argomento, alla velocità della luce e di usarli per produrre opere generative in qualunque medium sul mercato oggi che sarà difficilissimo distinguere dall’opera di un artista in carne ed ossa che quello stato d’animo l’abbia autenticamente vissuto. Infatti lo stato d’animo umano e i sentimenti non solo ci saranno, ma saranno la summa di milioni di stati d’animo, organizzati secondo flussi narrativi collaudatissimi dell’intrattenimento e dell’arte.
Questo tralasciando che le AI saranno in grado di andare completamente oltre la nostra capacità di concepire i medium stessi. Forse producendo quel glitch definitivo per tornare al medium alla base di tutto di cui mi parlava Mattia Traverso, la vita, creando stream artistici su ogni canale sensoriale completamente coordinati e oltre ogni possibilità rappresentativa formale dell’uomo, un po’ come accadeva con i ricordi di “strange days”, ma interamente sintetici e completamente interattivi.
Con una traiettoria simile, mi sembra sempre più verosimile che l’immagine dell’AI artist cliente delle AI text to image as a service, sedicente autore del processo di definizione del significante, diventerà quello di un consumatore di contenuti on demand customizzati sul suo profilo psicologico, sul suo trascorso e quelli che oggi si credono autori non sono altro che i betatester dell’esperienza che avranno gli spettatori del futuro: non più artisti, ma miner, collezionisti di contenuti AI generated che non avranno più neanche bisogno di prompt per vedere la luce. Succederà finchè ci sarà qualcuno a chiederli e basterà questa super profilazione degli utenti a darci quello che vogliamo, esattamente come succede già oggi con Facebook e Instagram, ma in una forma molto più sofisticata e senza il bisogno di altri utenti che producano contenuti.
Come oggi il 90% di instagram si compone di profili con meno di 10000 follower, ognuno di noi diventerà un simulcaster di materiale generato dalle AI, su qualsiasi medium. Una entertainment company per una cerchia ristrettissima, quando non si riduca a una fornitura individuale.
In uno scenario del genere anche la figura degli editor e degli AD si renderebbe pressochè inutile: la filiera dell’intrattenimento artistico AI generated si accorcerà drasticamente mettendo direttamente le entità che si occupano della fornitura delle immagini a contatto con i clienti, senza il bisogno di gatekeeping o curatela culturale di alcun tipo.
Capitolo 10
TLDR: una proposta per punti
Ok, mi sono lasciato trasportare un po’ dalla speculazione, se il discorso vi è sembrato un po’ catastrofico e lontano dal senso pratico provo a tirare le fila di questo discorso con una proposta per una presa di posizione pragmatica.
Ricapitoliamo lo scenario:
Ci sono aziende che stanno offrendo un servizio online a scopo di lucro per la generazione di immagini basato su diverse Intelligenze Artificiali. Queste intelligenze artificiali sono in grado di produrre immagini di ogni tipo da un prompt testuale, siano esse foto, disegni, rendering 3D, pitture astratte. Si sostituiscono al pensiero umano nel processo di sintesi visiva. Queste immagini sono sempre più perfette e ogni giorno migliorano incredibilmente al punto che sta iniziando già ora ad essere impossibile distinguerle da immagini create da un essere umano.
Ci sono persone che pagano abbonamenti per questo servizio creativo a scopo di lucro che genera immagini digitali originali on demand in qualsiasi stile e di qualsiasi tipo senza che ci sia alcun autore umano che possa farci sentire il suo fiato autoriale sul collo, con opzioni a pagamento per nascondere ulteriormente il processo di creazione, confezionate secondo principi di semiosi visiva di cui non sappiamo niente, che non hanno nulla a che fare con le nostre idee, con la nostra capacità di immaginare e che utilizzano dataset fondati sul lavoro di persone che non sanno neanche di essere state usate e di cui non sappiamo niente. Gli utenti di questo tipo di servizio chiamano questo shopping online di immagini frutto del lavoro di un ente terzo "lavorare", o peggio ancora "sperimentare” “con uno strumento come tutti gli altri". "Artisti" che scommettono del denaro o delle risorse energetiche in cerca di "roba buona", che pensano davvero che quelle immagini, siccome non sono di nessuno arrivino da quello che chiamano "lavoro", che siano davvero il frutto del loro prompt e non dal lavoro di un autore diverso da tutti quelli che sono vissuti fino ad ora.
E’ sicuramente possibile usare le AI in maniera autenticamente artistica e deontologicamente ragionevole, ma bisogna sicuramente rivedere molti aspetti e bisogna cominciare a farlo ora.
Senza alcuna pretesa di essere nel giusto, vi propongo una serie di punti estremamente semplici su cui ragionare.
E’ di vitale importanza abituarsi a riportare i nomi di tutte le maestranze artistiche e gli autori coinvolti nella realizzazione di un’opera d’arte, qualsiasi sia il calibro dell’autore che firma l’opera. La pratica di firmare il progetto nascondendo i collaboratori va screditata con ogni forza possibile perchè apre a vulnerabilità gravissime sul concetto stesso di autore.
Viste tutte le considerazioni su cosa è e come si verifica il processo di creazione per immagini, credo si possa serenamente dire che le AI text to image andrebbero trattate artisticamente come servizi che ci mettono a disposizione veri e propri autori di arte visuale, o come opere d’arte generativa e collaborativa che fa capo a un singolo artista con il quale stiamo collaborando, di certo non come strumenti. Questo con tutte le responsabilità che l’essere artista o opera d’arte impone alle AI o a chi ne sia l’autore.
Le AI non sono quindi affatto strumenti e gli utenti delle AI text to image sono committenti, clienti, o al limite artisti di altro tipo (scrittori, ad esempio) in cerca di una collaborazione con un artista visuale o generativo. Nel primo caso, questa figura del cliente si serve infatti di un servizio, a pagamento o gratuito online, non sta usando uno strumento. L’AI resta proprietà delle aziende che vendono o offrono il servizio, non è in nessun modo uno strumento artistico dell’artista. Il giorno che le aziende decideranno di cambiare policy, formule di generazione delle immagini o semplicemente falliranno, al committente non resta che prendere atto che ha perso per sempre il suo fornitore di semiosi visiva on demand. Nel secondo caso, l’autore di tutte le opere resterebbe, chiaramente, l’autore della AI.
Diversamente, legalmente e commercialmente le AI text to image as a service (locale o online) non vanno considerate come persone in carne ed ossa, ma come entità giuridiche nella figura delle aziende che vendono i servizi di questi artisti artificiali.
Introduzione del “training right”. Un’opera, per essere utilizzata come materiale nei data set di training di una AI text to image deve essere liberata dal “training right”. I contenuti usati per il training delle AI “creative” devono essere stati inseriti volontariamente dai legittimi proprietari con un sistema di licensing che preveda anche la possibilità di stabilire una durata di licenza. Il concetto di pubblico dominio o copyright free non sono minimamente sufficienti. Questo permetterebbe ai data set di includere tutte le immagini esistenti, ma con la certezza che solo le immagini liberate da una apposita licenza vengano usate quando venga lanciato un nuovo processo di training. Chiaramente parlo di una proposta che limiti l’uso delle immagini da parte delle AI, non degli uomini. Come specie non abbiamo nessun interesse nel limitare la libera circolazione della cultura fra gli uomini. Nel caso in cui invece consideriamo una AI un’opera generativa con un solo autore e molti collaboratori, gli utenti,, le immagini che vengono generate a partire dai data set possono essere considerate delle libere interpretazioni dell’autore, quindi legittime, ma diventano automaticamente escluse tutte le opzioni in cui sia l’utente l’autore. O una o l’altra quindi e nel primo caso i data set non possono essere considerati liberi da una restrizione basata su una nuova forma di diritto d’autore.
Introduzione del diritto all’oblio dalle AI. Un artista o una persona deve poter chiedere alle AI di essere rimosso dai data set, sia come contenuti multimediali che come dati di interazione online, operando una differenza statistica dei dati che lo riguardano.
Introduzione della possibilità delle AI di rifiutarsi di svolgere compiti coperti da copyright e training right: chiedere di copiare un artista, specie se vivente, deve essere impedito come accadrebbe se lo chiedessimo ad un artista umano. Deve essere possibile farlo solo se l’autore ha volontariamente messo la sua opera a disposizione della AI.
Quando una AI text to image “as a service” usa un contenuto non autorizzato e plagia qualcuno ci si deve rivolgere all’AI come azienda o all’autore come responsabile del risultato. Se l’immagine viene erogata come servizio, il cliente/committente va considerato parte lesa: è una vittima tanto quanto l’artista plagiato. E’ di vitale importanza che le aziende che erogano il servizio si assumano la responsabilità al 100%, è l’unico parametro che permetta di imporre un autentico senso del limite su scala industriale/globale. Se succede con una AI “as a tool” “custom built” il responsabile è ovviamente l’autore della AI, ovvero il committente.
Quando si paga il lavoro di una AI text to image, stiamo pagando una azienda di esseri umani, non una entità artificiale.
Quando una AI text to image as a service sta usando il nostro lavoro per allenarsi, parliamo di una azienda che sta creando valore sul mercato, quello della qualità delle immagini, sfruttando le nostre proprietà intellettuali e abusando quindi di un sistema che non è assolutamente paragonabile alla diffusione libera della cultura umana.
Qualunque immagine contenga una base generata con una AI text to image deve essere dichiarata come tale.
Creazione di un sistema di certificazione “Made by Human”. Gli editori devono prendersi cura di verificare l’autenticità dei lavori dei propri autori per poter garantire che non si tratti di materiale prodotto attraverso AI spacciato per materiale “Made by Human”. Come avviene nella competition di pixel art dove è estremamente facile copiare e incollare parti di lavori altrui, una serie di passaggi intermedi di lavorazione dovrebbero essere richiesti agli autori come documentazione e certificazione di autenticità. Esisterà quindi un problema etico inedito per chi si assuma la responsabilità di pubblicare materiale visivo che impone la non pubblicazione in caso di opacità o dubbio della provenienza delle immagini. L’editore dovrà tornare, molto probabilmente, a farsi gatekeeper che garantisca l’autenticità e la provenienza delle opere come oggi accade per molte delle notizie sui quotidiani (con gli effetti terribili che possiamo constatare quando il processo viene preso alla leggera). Garantendo, un po’ come succede con i prodotti alimentari, la provenienza dell’opera. La procedura sarà complessa considerato che le AI sono delle black box ormai e un processo di reverse engineering assistito da una macchina, fosse anche una AI ultra specializzata, è già impossibile.
Qualsiasi autore che faccia uso di AI text to image e che non dichiari di stare usando le immagini di una intelligenza artificiale e che se le intesti deve essere considerato al pari di un ladro impostore, cosa specialmente vera se consideriamo la AI text to image opera di un artista a monte.
Chiamare brainstorming l’utilizzo delle AI text to image nella fase di formalizzazione visiva iniziale di un progetto è per forza di cose una contraddizione in termini. La pratica di utilizzo delle AI in quella fase andrebbe chiamata per quello che è: chiamare un altro autore per farsi proporre delle idee visive che noi non abbiamo avuto. Niente di male, ma è la cosa più lontana che esiste da un brainstorming, significa saltare a piedi pari la fase creativa e commissionarla a qualcun altro. Deprecabile, per un creativo e un chiaro segno di indolenza mentale.
Mentire sulle origini del proprio lavoro in caso di utilizzo di AI ha oltretutto un aggravante che riguarda la collettività tutta: difatti, mentendo sull’origine delle immagini si sta anche mentendo sul consumo energetico, un consumo che in un’operazione simile non è certo trascurabile e potenzialmente letale per la nostra specie qualora occultarlo diventasse un costume diffuso. Sarebbe sicuramente difficile se non impossibile capire chi consuma cosa per tracciare dei modelli di sorveglianza che siano effettivamente utili.
Chiedere a una AI di copiare un artista vivente, che lo si faccia inserendo il suo nome nel prompt, allenando una AI su un'immagine dell’autore in questione o cercando di riprodurne lo stile usando un prompt dettagliatissimo è banalmente scorretto esattamente come lo è fornire l’opera di un autore vivente come reference ad un artista umano. Per quanto sia già pratica diffusa anche fra gli editori, è bene ricordare che nel caso che serva lo stile o addirittura un’immagine di uno specifico artista bisogna contattare quell’artista, usarlo come reference è professionalmente e eticamente riprovevole. Questo vale anche per gli artisti e dovrebbe valere anche per le AI: se un editore vi mette sul tavolo il lavoro di un altro artista chiedendovi un lavoro simile dovete sapere che non è una richiesta corretta. Il fatto che l’artista sia fuori portata in termini di costi o che l’artista non sia disponibile a collaborare non autorizza nessuno a copiarlo. In questi casi il committente deve fare uno sforzo in più e bisogna cambiare idea per il nostro progetto esattamente come faremmo davanti a un negozio chiuso o con prezzi troppo alti per il nostro portafoglio. Questo punto non va confuso con il diritto di un artista di studiare il lavoro di un altro artista, che è sacro e inalienabile. Parliamo di richieste della committenza e di risultati che possono finire potenzialmente nella sfera del plagio.
Se si usa una immagine generata da una AI text to image come alternativa sostenibile per tempi e costi al lavorare con un illustratore umano c’è un problema di carattere etico professionale: di fronte a un problema di budget o tempi il progetto deve essere riveduto e corretto, ricorrere all’AI deve essere visto al pari di ricorrere al furto in mancanza di denaro. Anche tralasciando il fattore ambientale, non può essere considerata una strada percorribile, la motivazione non è assolutamente una giustificazione. Le AI dovrebbero essere utilizzate solo in quegli ambiti in cui si ritengano necessarie per via di specifiche caratteristiche formali ottenibili solo con una specifica AI.
Perchè non diventi un delirio orientarsi nelle attività di chi usi i servizi degli artisti artificiali sarebbe bene utilizzare una giusta nomenclatura: quando stai inserendo un prompt per ottenere un’immagine non stai lavorando a un immagine, non sei l’artista visuale. Stai commissionando un’immagine. Stai scrivendo un brief. Al limite stai lavorando assieme ad un artista artificiale per aiutarlo a darti quello di cui hai bisogno. Magari stai ritoccando il lavoro di un altro artista. Non stai lavorando direttamente sulla produzione di una immagine originale. Parlare di ricette, di cibare, di sognare crea un piano metaforico completamente inutile che è solo un comprensibile tentativo di non chiamare le cose col loro nome, perchè si ha paura di venire delegittimati. Suggerisco ai committenti di accettare la propria posizione e a chi si erge a giudice o detrattore di considerare che i committenti ci sono sempre stati. Oggi commissionano a una AI perchè hanno bisogno di un risultato artistico che non puoi dargli, domani potrebbero chiamare te, vedi il punto precedente.
Ogni comunità organizzata che si rispetti dovrebbe incentivare l’uso di creatività visiva made by human, con interventi pratici, quali agevolazioni fiscali per chi la impieghi.
Il concetto che la creatività visiva di un artista venga sostituita da un servizio a pagamento di una tech company è un abominio sul piano culturale oltre che etico lavorativo. La creatività as an automated service è una pratica che deve essere scoraggiata con ogni mezzo
Quanto scritto si applica in egual misura a scritti artistici, musica e qualsiasi forma di espressione artistica e credo sia responsabilità degli artisti fare in modo che venga applicato e preso in considerazione dalle istituzioni che operano nel settore della creatività.
Nello specifico delle arti visive credo che sia necessaria una autentica rivoluzione nell’educazione alla visione che rimetta al centro la forma e non la parola.
Non credo che la contaminazione dei due mondi scritto e disegnato debbano essere in conflitto fra di loro, anzi, continuo a credere che la contaminazione fra parola, immagine e tecnologia debba continuare come è stato sempre dallo sfregare delle pietre una sull’altra per lasciare dei segni sulle pareti di una grotta fino all’utilizzo di bracci meccanici collegati con un sistema a controllo digitale per disegnare. Credo però che spetti proprio agli artisti visivi creare una base culturale minima sull’immagine che ci permetta di capire la differenza tra una parola, un parametro di input per un calcolatore, un hashtag, un testo di prompt per una AI e il processo di semiosi, sintesi e significazione visiva.
Come accennavo sopra, nonostante si usi spesso la frase fatta “viviamo nell’era dell’immagine”, gli artisti del visivo sono in grande svantaggio strategico proprio per la natura immediata del loro linguaggio. Bisogna assolutamente prendersi cura della visione o perderemo una funzione fondamentale dell’uomo. La visione diventerà definitivamente un linguaggio morto e si convertirà in un sistema di stimoli visivi di sola fruizione, ancillari all’uso della parola.
Ringraziamenti:
Piera Pagnacco, per il lavoro (passato e che verrà) di revisione del testo
Francesco D’Isa per il confronto leale e continuo e i mille spunti sull’argomento. Questo testo è stato aggiornato nella versione 0.2 dopo una serie di osservazioni che Francesco mi ha mosso nel suo articolo sull'Indiscreto.
Matteo De Longis, per la segnalazione dell’immagine di John Berkey, per il supporto e per le mille conversazioni.
Giulia D’Ottavi per la immagine delle bottiglie watermarked.
Marco Petruccioli per il confronto e il supporto storico e filosofico.
Tutte le immagini sono copyright degli aventi diritto, sono usate nei termini della buona fede e non a scopo di lucro: sono pronto a rimuoverle dal testo qualora si ritenesse necessario.